

一、Midjourney中文版介绍
点击打开网站:Midjourney中文版平台Midjourney学习笔记
产品特点:
Midjourney中文版平台为:全中文界面、安全稳定、国内可用、快速出图,一键创作、功能齐全,不断更新!出图质量不变!使用方法不变!不用科学上网!不用加速器!不用魔法!标准版订阅45.8元/月,非常推荐所有人使用!
国内用户如果想使用官方的Midjourney比较麻烦,不仅要懂得科学上网,很多人一开始就可能会卡在注册、订阅的环节,而且Midjourney官方的订阅费价格贵,使用这个Midjourney中文版,它是基于官方Midjourney接口开发,对接的还是官方出图,所以和官方是一样的,通过我的综合对比,Midjourney官方和国内Midjourney中文版,出图效果是一毛一样的,没有任何差异,这就说明接口是官方的接口,很多人迷信官方,但复杂的注册的和订阅方式,加上不稳定,最终折腾了半天,浪费了你的时间和金钱,还不如一开始就使用国内版本。全中文+友好的界面,关键是便宜啊!
有些人说了,这是山寨的,出图质量不行,骗子工具...好!我们来实事来说话,下面,我们来使用一段咒语,测试一个两个版本的区别在哪?
首先,我们来看官方的:


再看看中文版的:
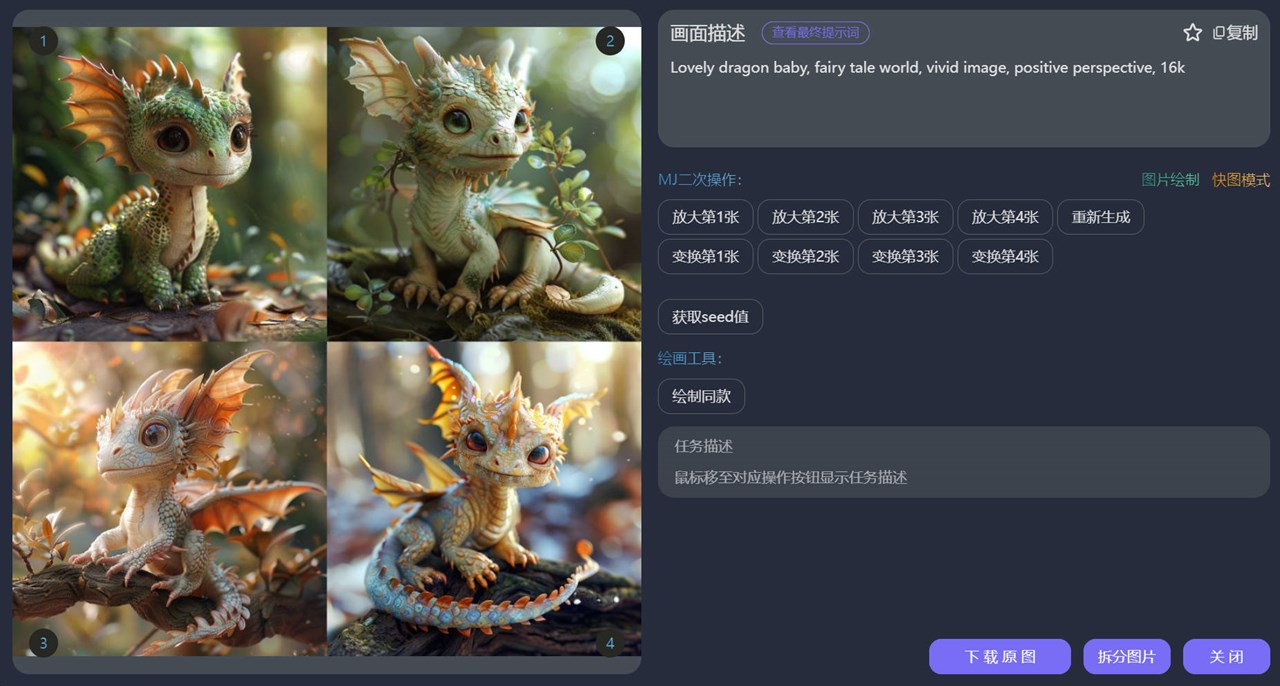

麻烦大家瞅瞅,区别在哪儿???
Midjourney中文版的订阅也非常简单,可以选好订阅版本后,直接用微信和支付宝来支付,而且同版本的价格相对国外来说,便宜很多,对于初级小白来说,真是非常友好啊!
Midjourney中文版订阅费用一览表:
| 内容 | 基础版(体验版) | 标准版(高级版) | 专业版 | 季度版 |
|---|---|---|---|---|
| 按月订购 | 28.8元/月 | 45.8元/月 | 88.8元/月 | 128.8元/月 |
| 快图模式 | 75张图 | 100张图 | 220张图 | 300张图 |
| 常规模式 | 300张图 | 不限图片数量 | 不限图片数量 | 不限图片数量 |
| 最大任务量 | 2个并发 | 2个并发 | 3个并发 | 3个并发 |
| AI聊天 | 不限次数 | 不限次数 | 不限次数 | 不限次数 |
| AI换脸 | 不可用 | 可用 | 可用 | 可用 |
Midjourney英文版订阅费用一览表:
以下表格内,注明的人民币的换算数额,是一个大概的额度,说明一下!
| 内容 | 基础版(Basic) | 标准版(Standard) | 专业版(Pro) | 超级版(Mega) |
|---|---|---|---|---|
| 按年订购 | 70元【8美元】/月 | 210元【24美元】/月 | 420元【48美元】/月 | 840元【96美元】/月 |
| 按月订购 | 87元【10美元】/月 | 262元【30美元】/月 | 525元【60美元】/月 | 1050元【120美元】/月 |
| 快图模式 | 200张图 | 900张图 | 1800张图 | 3200张图 |
| 慢图模式 | 不支持 | 不限图片数量 | 不限图片数量 | 不限图片数量 |
| 隐私模式 | 不支持 | 不支持 | 支持 | 支持 |
| 最大任务量 | 3个并发 | 3个并发 | 12个并发 | 12个并发 |
平台常见问题
Midjourney中文版订阅费为什么比官方便宜很多?
通过以上对比,本站在快图模式条数上适当做了调整(因为根据实际使用情况下,正常我们根本不需要那么多条),所以定价便宜,显然要实惠很多,注册和订阅也非常方便,强烈推荐使用!
充值了怎么还是不能用?
先看看我的-登陆界面,请确认订阅时绑定的微信号或者手机号,是否绑定了微信或者手机号码。
显示关联任务失效?⚠️
这是因为有通道因多次触发敏感词被封,导致不能进行关联任务,可以进行重新绘制。在出图时就尽量进行后续操作,以免任务失效。
快图模式与常规模式?
我们有两种图像生成模式:“快图模式“和"常规模式",也就是对应官方的Fast模式和Relax模式。快图模式将会立即为您提供 GPU运算,这是最高优先级的处理级别,会有点贵。Relax模式会根据MJ系统当前使用总人数和绘画任务数,将您的任务排在其他人后面,正常情况下2-5分钟,高峰期会超过10分钟。
我想要更多的快图可以吗?
除了您的常规订阅外,您还可以选择订购快图加速包,它们没有过期时间,直到您使用完。
图生图,图混图上传不了图片?
检查图片是否是png格式,和图片是否超过10兆。
我的图像可以商用吗?
只要是您订阅后自己画的图,就可以以任何方式自由使用您的图像,商业使用没问题。
生成的图片为什么有些没有成功?
即便您用国外的官网,也会有3-5%的失败率,原因通常是:短时间内重复提交、有违法违规的指令、参数错误,本站整体的失败率也是3-5%,但失败的不会占用您应享有的额度。
U、V、🔄介绍
U:U1U2U3U4 按钮放大对应的某一张图像,可生成所选图像的更大版本并进行更多细节操作。
V:V1V2V3V4 按钮为对应的图像的增量变化,可会生成与所选图像的整体风格和构图相似的新图像网格。
🔄 按钮为重做重新运行作业,它将重新运行原始提示,生成新的图像网格。
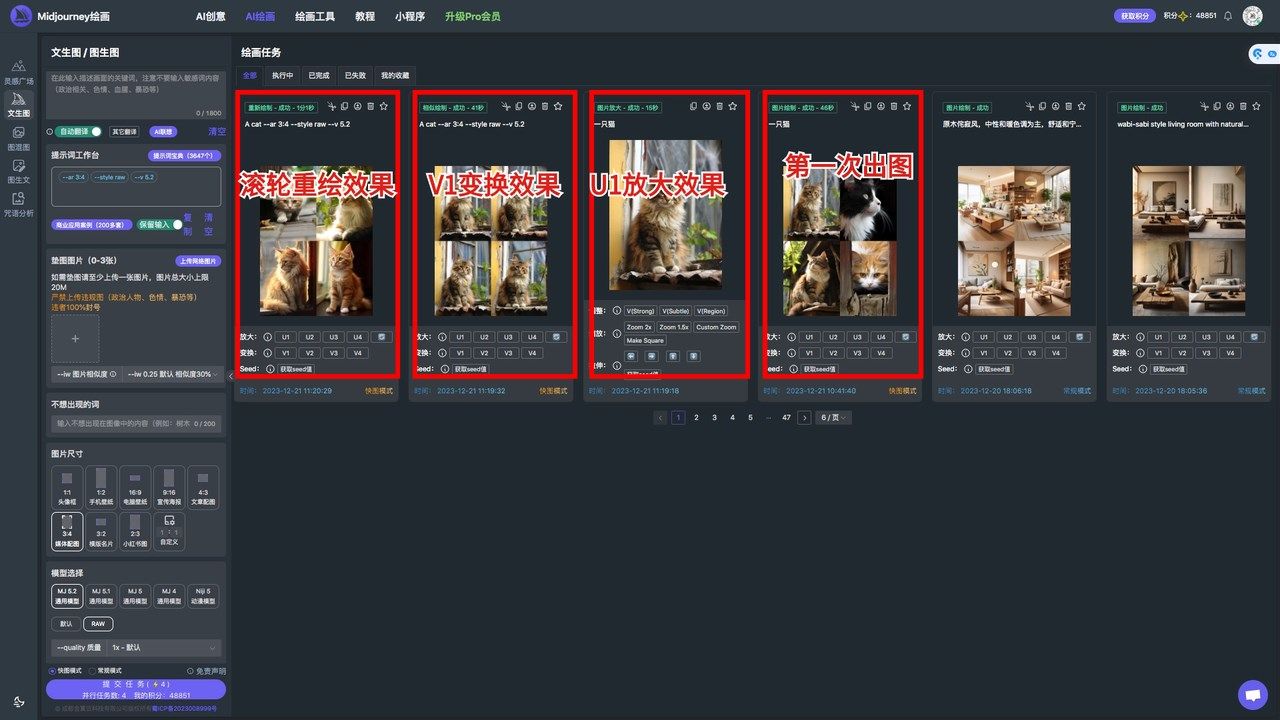
缩2倍,1.5倍怎么用?
喜欢生成的图像,但希望它更高或更宽?“缩2倍或者1.5倍”选项允许您将放大图像的画布扩展到其原始边界之外,而不更改原始图像的内容。新扩展的画布将根据提示和原始图像的指导进行填充。
🔎自定义:使用自定义缩放更改提示
🔎 自定义允许您在扩展图像之前更改提示和zoom值 ,--zoom接受 1-2 之间的值。从而更好地控制完成的图像。例如,将提示更改为“Framed pictures on the wall “ 会产生以下结果:
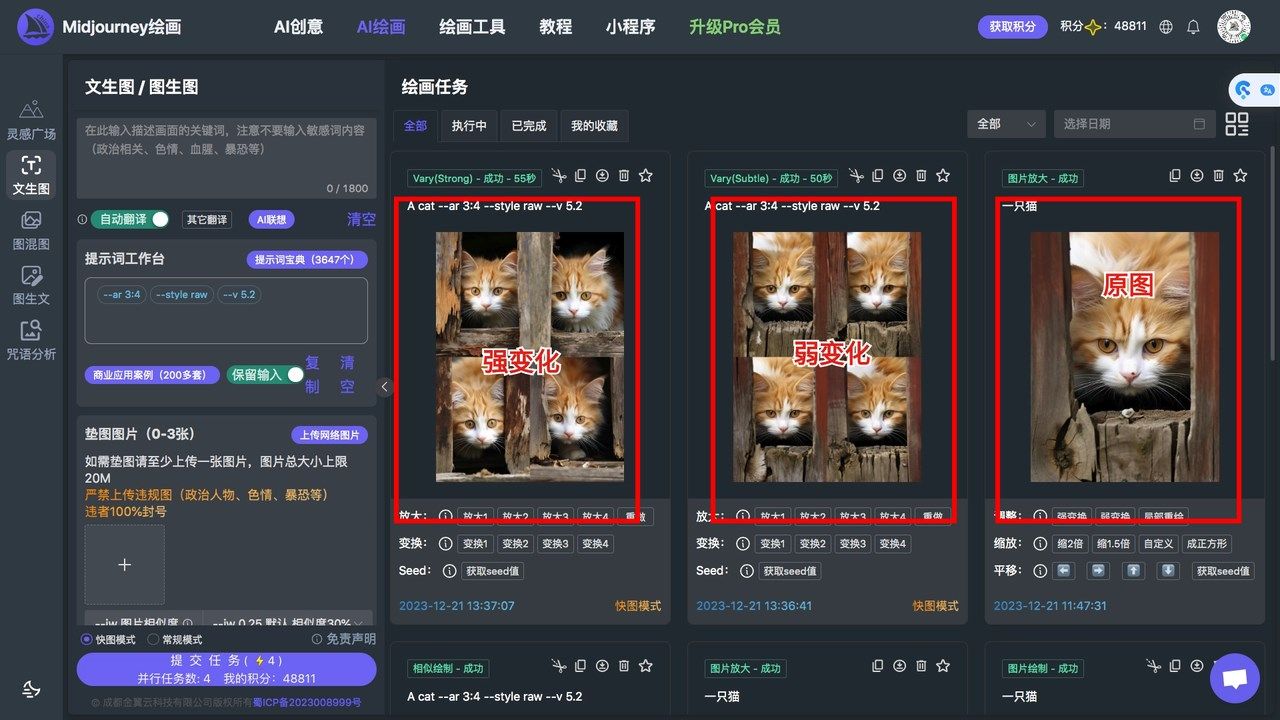
3.Vary(strong),Vary(Subtle)表示对图片进行微调也可以修改提示词
⬅️ ➡️ ⬆️ ⬇️
使用“平移”按钮可以沿选定方向扩展图像的画布,而无需更改原始图像的内容。新扩展的画布将使用提示和原始图像的指导进行填充。
以左右扩展举例(请看视频):先生成一组图,选择一张喜欢的放大(U)
Make square
Make Square可以调整非方形图像的纵横比使其成为方形。如果原始宽高比较宽(横向),则会垂直扩展。如果它很高(纵向),它将水平扩展。
重绘功能
记住:需要放大U喜欢的一张才能进行后续操作
二、Midjourney中文版入门
首先,打开Midjourney国内版的网站,你会发现网站界面和原版布局都差不多,只是更符合国人的使用习惯,全中文界面,版块布局也很合理,结构一目了然!

注册方法
找到[登录/注册],直接用手机号、邮箱、微信,任一一种方式来注册,快捷而高效,没有繁琐的操作方式,三分钟就搞定了!
使用方法
国内版Midjourney使用方法非常简单,根据中文界面的意思和功能模块,结合视频教程来操作,三天就大概把里面的所有功能全掌握!
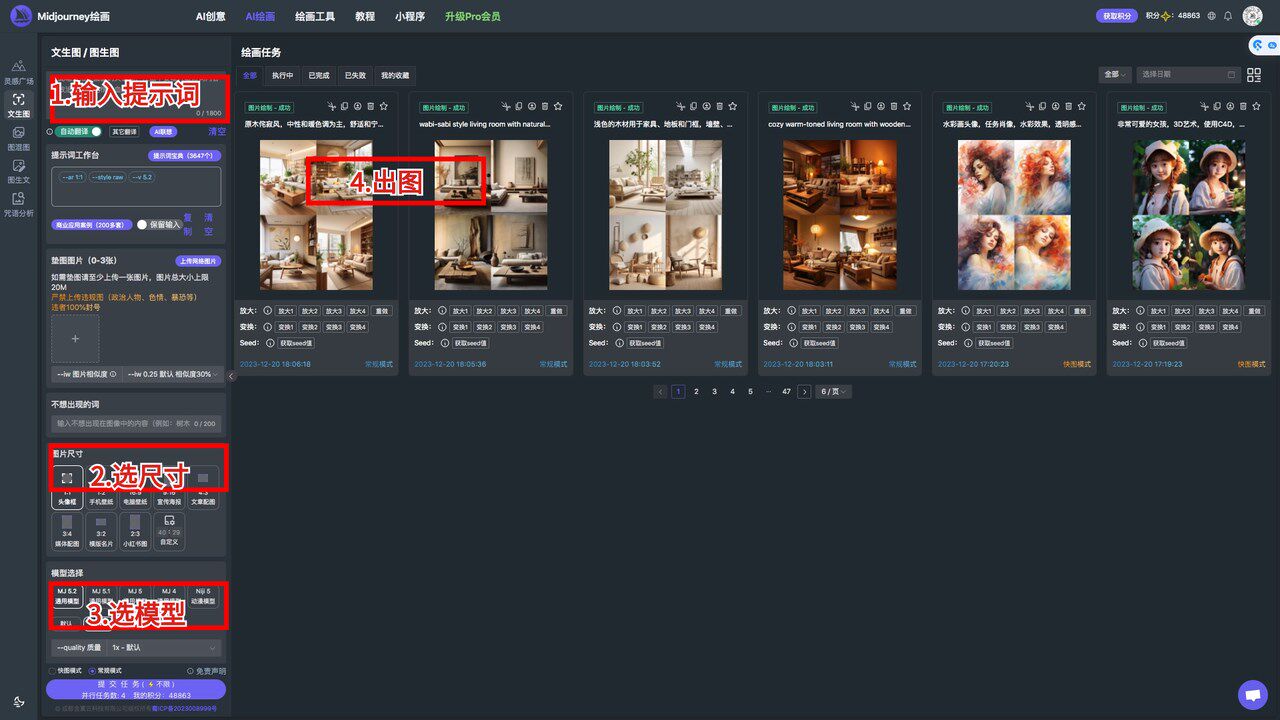
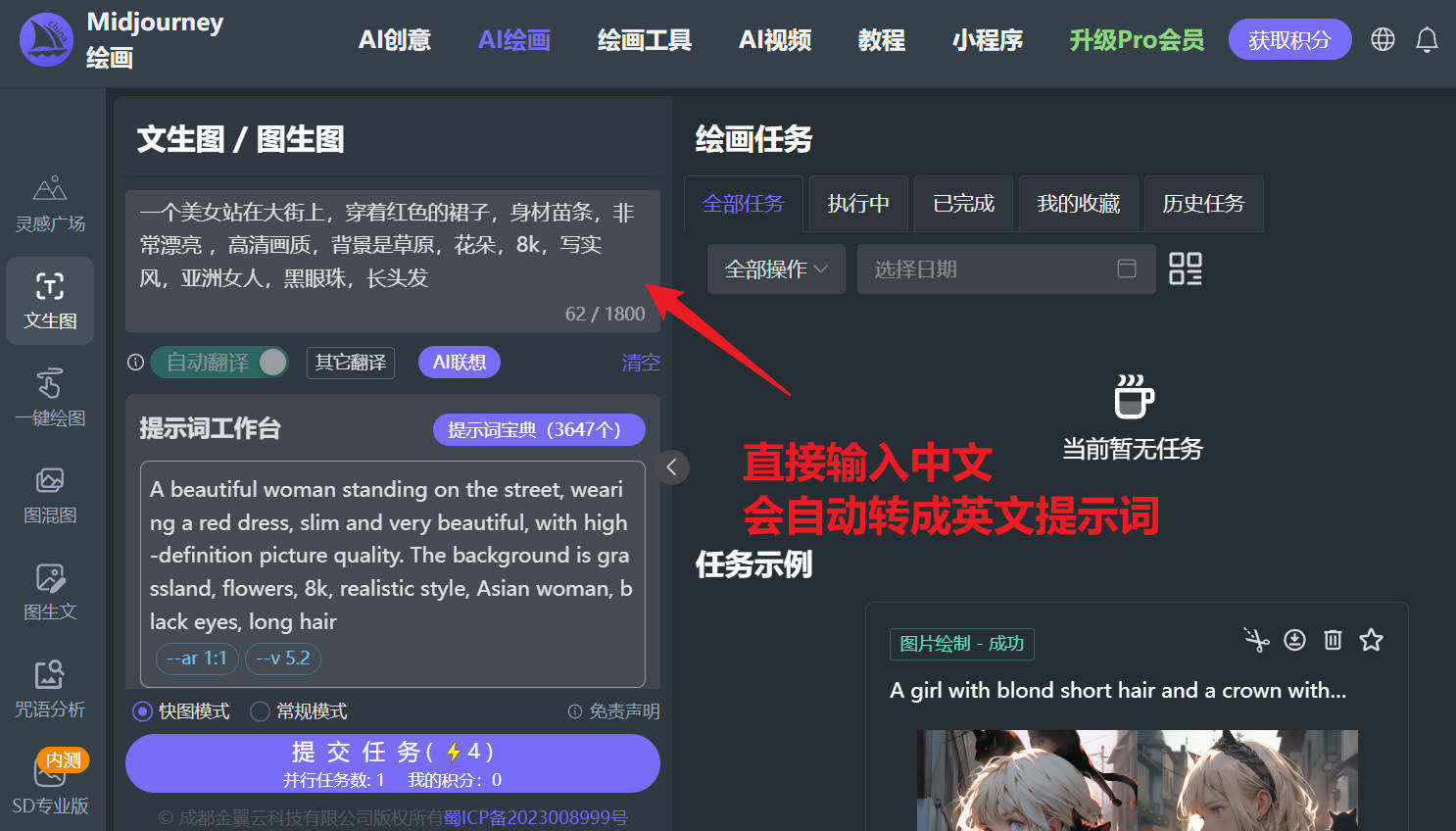
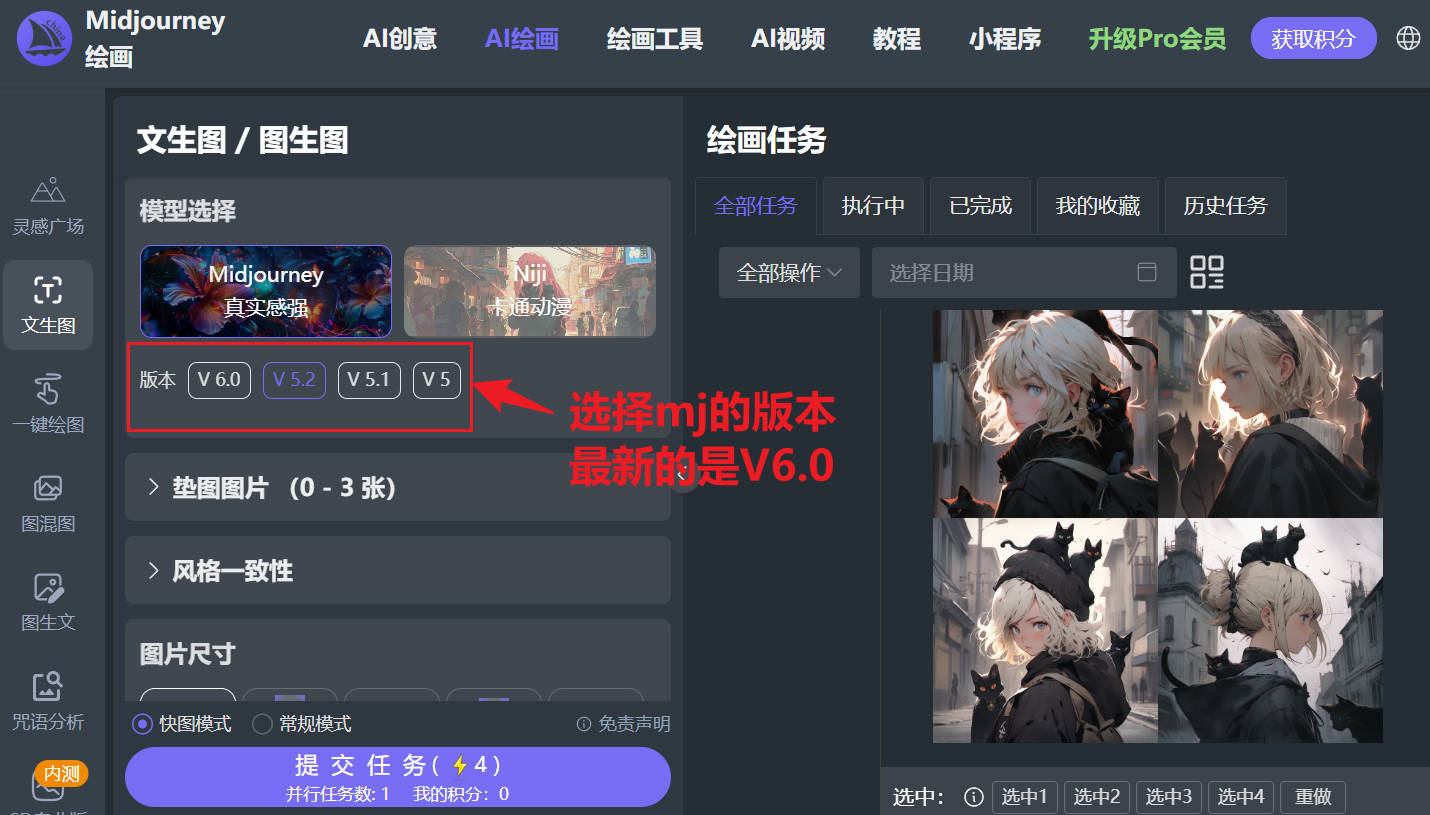
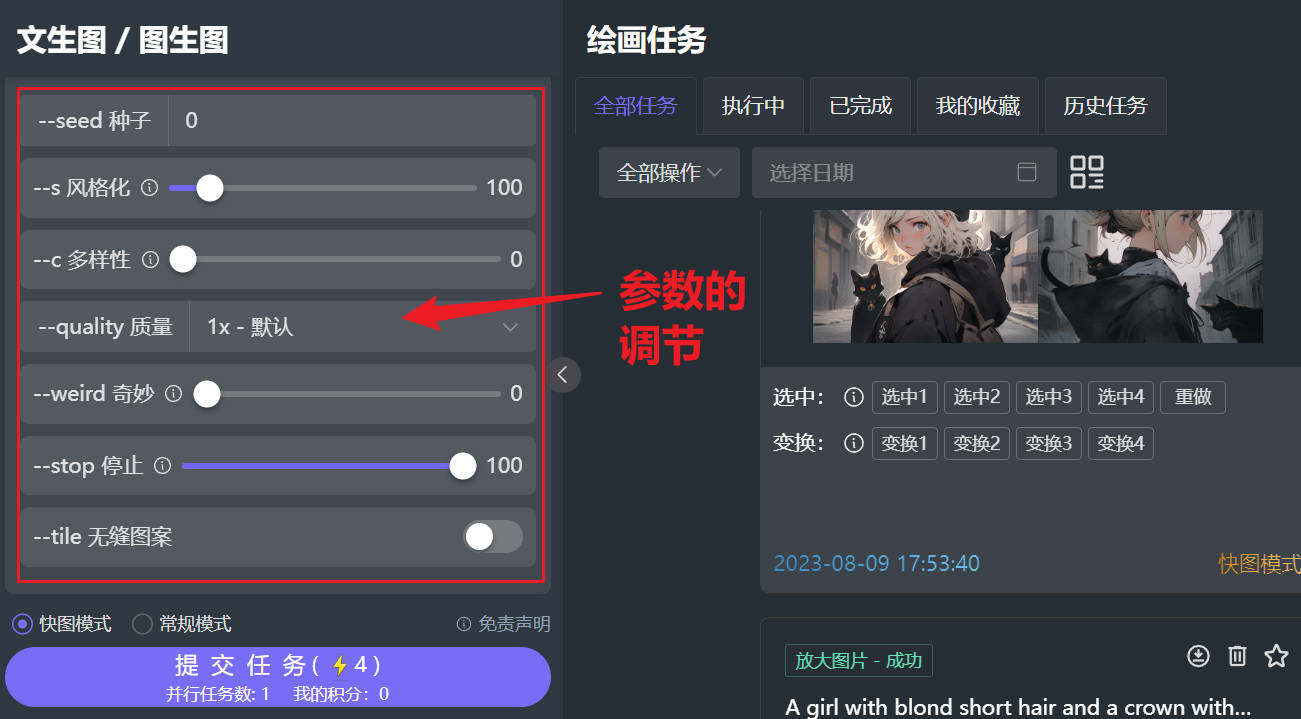
最后,提示词和调节参数以及图片尺寸都设置好了后,点击提交任务,它将在1-5分钟给你出四张图,在四张图中再作挑选、变换、放大、优化、调节等操作!
还不懂?(请看视频案例)
1、平台设置了自动翻译,可直接写中文提示词自动翻译成英文,如果需要更准确可以先翻译成英文在输入进来。
2、尺寸的选择根据需要,每个尺寸适合什么,在界面上也给大家标出来了,同时你也可以自定义尺寸。
3、每个模型代表什么什么意思:请看第六部分:各个模型的版本差异
三、Midjourney进阶教程
1、 Prompt提示词基本结构
在 Midjourney 的提示词 Prompt 分成三个部分。
Image
这个属于选填,它是图片的 URL 地址,而且必须是公开可访问的地址,图片格式仅支持 png、gif、jpg。你最多只能放两张图的 URL,或者一张图的 URL + 一段话。
Text Prompt
这个就是你希望 AI 生成的图片的描述。
Midjourney 跟 ChatGPT 有点不一样:无法理解句子结构和语法:Midjourney 没法像 ChatGPT 那样懂你说的话。类比的话,Midjourney 更像是命令式编程,ChatGPT 更像是声明式编程,你需要给 Midjourney 完整的指令,它才有可能生成你满意的结果。Midjourney 有违禁词的设计:有些词语无法输入,比如 🍑 emoji 就没法输入,因为这个 emoji 是 butts 的俚语,常常会导致模型生成一些不太好的图片,所以也被禁止了。
2、常用参数说明
| 基本参数 | 解释 |
|---|---|
| --ar | 纵横比-aspect,或-ar更改生成的纵横比。 |
| -chaos |
改变结果的变化程度。更高的价值观会产生更多不寻常和意想不到的世代。 |
| --iw<0-2> | 设置相对于文本粗细的图像提示粗细。默认值为1 |
| --no | 负面提示,-no plants会尝试从图像中删除植物 |
| --Weird |
通过实验-weird参数探索不寻常的美学 |
| -tile | 参数生成可用作重复图块以创建无缝图案的图像 |
| -stop<10-100> | 使用该-stop参数在流程中途完成作业。以较早的百分比停止作业可能会产生更模糊、不太详细的结果 |
| --quality <.25,.5,or 1>, 或-q<.25,.5,or 1> | 您想要花费多少渲染质量时间。默认值为,值越高,使用的GPU分钟数越多;较低的值使用较少 |
| --stylize |
风格参数,默认值100,范围0-1000 |
| --V<5.1,5.2,6> | 使用不同版本的Midjourney算法 |
| --seed |
Midjourney机器人使用种子号来创建视觉噪声场(例如电视静电),作为生成初始图像网格的起点。种子数是为每个图像随机生成的,但可以使用--seed或--sameseed参数指定。使用相同的种子编号和提示将产生相似的结局图像 |
中文版参数如何使用:
3、撰写 Text Prompt 注意事项
Midjourney 跟 ChatGPT 在 prompt 的使用上有很多不一样的地方,Midjourney 基本上是不懂语法的,所以即使你语法错了,只要词对了,也能生成图片。所以,prompt 不是越长越好。特别是各种定语从句,它根本就不懂,还不如把指令用逗号隔开,一个个输入。以下是官方推荐的语法建议:
使用形容词+名词的词序来替换介词短语。
hair flowing in the wind 应该改为 flowing hair
a carrot for a nose 应该改为 carrot nose
使用非常具体的动词来替换介词短语。
a girl with a flashlight 应该改为 a girl using a flashlight
a girl with a big smile on her face 应该改为 smiling girl
最后, Midjourney 是不会区分大小写的。
单词
在单词的部分,Midjourney 跟 ChatGPT 有点类似,它对同义词的理解也不是很好。比如举两个例子:
big (大)这个词,到底指多大?越具象的大,对于 Midjourney 来说,效果越好,比如用 gigantic 就比用通用的 big 好。cats(猫)这个词是个复数,但到底是多少只?对于 Midjourney 来说,two cats(两只猫)比 cats 更明确。
另外,Midjourney 还能用 emoji 代替单词(我觉得本质上 emoji 也是单词)。
如果你想让 Midjourney 不生成某样东西,就需要用到 参数 — no。你不说,模型就会随机给你,因为图像信息的信息量远超过文字,所以很多时候,Midjourney 会随机填充一些内容给你,它既是缺陷,也是亮点功能。因为当你不在 prompt 里说明这些词时,你就能获得发散的结果。如果你想减少这些随机性,就需要用到一些 prompt 框架(或者所谓的模板)。
参数
Midjourney 允许你在 prompt 里加入参数,而且这些参数相对来说一致性都比较好,所以如果你想实现的功能,参数里支持,那优先使用参数,而不是在主体里描述。
4、场景应用及技巧
场景1:Stock Photo
Stock Photo 直译为图库图片。一般你能在一些图库网站上找到,这些图片通常来自一些摄影师或设计师。部分图片因为版权的原因,如果你需要使用则需要付费。大部分使用 Stock Photo 的用户都是一些设计公司,或者广告公司。你应该常常能看到这类图片,比如最经典的两人握手照片:

我认为 AI 生成图片对图片库行业和摄影行业冲击非常大,V5 版本基本上满足了我的 Stock Photo 需求。
临摹
我认为学习图片类的 prompt,跟学习画画是类似的,最好的学习方法不是直接用现成的提示词塔板,可以拿真图临摹,当你临摹了几张后,就会慢慢搞懂如何做出类似的图了。拿上面的那个握手图为例,我们仔细观察上面那张图,图中元素有什么:
1、主体是两个手握在了一起,并且看起来是两个亚裔男人。2、两人都穿着西装。3、背景看上去像是在办公楼的大门,两人可能是在握手告别。并且背景刻意进行虚化了,或者是使用照相机拍摄的。

总结信息:
主体:两个穿着西装的亚裔男人在握手告别
场景:办公楼大门
风格:stock photo,照相机拍摄
这时候,我们就能尝试写一下 prompt 了(英文水平不行可以用翻译软件)。
Midjourney 生成的结果如下:

Emm 🤔 好像跟我们的预期不一样。不要慌,刚开始用 Midjourney 一定会遇到这种问题,重要的是多尝试。
再来分析下为何生成了这样的图片?
首先图片的主体,或者说焦点,我们只需要「握手」,而不是两个人。照相模式好像并不能实现背景虚化?更像是一种图像风格,图四就像是一种老照片的风格。那我们调整下 prompt,增加焦点和背景虚化关键词:
再来看看生成的结果,结果好很多,图 1 和 图4 基本满足需求了,图 2 和图 3 裁剪一下,也能满足我们的需求。不过需要注意,Midjourney 在人手的生成上,暂时还有点问题,你细看图 2和图 4,其中有一个人的手有 6 个手指 😂,但我认为未来应该会修复:

那我们来总结一下 prompt ,该 prompt 分成以下几个部分:

第一部分(红色线):描述你想要的内容主体。
第二部分(蓝色线):描述主体背景/环境。
第三部分(黄色线):照片的焦点位置。
第四部分(绿色线):照片的风格或者说是特殊要求。
总结下之后,你是不是就总结出了一个模板了?😁
多实验
图片生成遇到不符合预期的情况不要慌,分析问题,然后使用控制变量法,一个个调整图片,不要急,上面我写的 prompt 还有一个地方,不知道各位有没有注意,就是开头的 stock photo,试试将这两个词删掉会怎样?
生成结果也依然满足需求,而且手指的数量也准确了,说明这个 Stock Image 对模型的影响不是很大。

善用图生图功能
用 Stock Photo 库会遇到以下几个问题:
1、图有版权,没法商用,或者说需要付费。
2、有些图,被很多人用过,其他人一眼就看出来这是商业图库的图。
3、图里的内容大体符合要求,但细节不符合要求,比如上图两个亚洲男性握手,可能换成一男一女,且其中一人是黑人会好一些。
要解决这3个问题,最好的方式就是让 AI 改一改原来的图片。让 AI 改图,只需要用到图生图「Image2Image」(或者叫 Blend / 垫图) 功能即可。操作步骤如下:
将你看到的不错的 stock photo 发给 Midjourney Bot(我还是以前面的那张握手照为例)
右键复制该图片的链接,然后粘贴到输入框,在链接后加个空格,接着输入你想要的内容,比如将其中一个人的手换成黑人,一个人换成女性:
生成的结果是这样的,我在 prompt 里没有提任何西装,以及场景背景信息,就说我要一个非裔的手,一个亚裔女性的手:

场景2:品牌 Logo
我们需要学习提示词吗?
垂直场景的 prompt,比如 Logo 相关的提示词有:
如果你以为只要看了别人的 prompt 用了别人的提示词,就能生成好的图片,那就错了。对于新手来说,我不建议各位直接上来就记prompt模版,因为写好一段 prompt ,你缺的不是提示词,而是对设计的理解,甚至是想象力。比如本章节的 Logo 设计,如果你根本不知道 Logo 包含哪些元素,适合什么风格,你懂再多的提示词也没法生成满意的 Logo。Midjourney 跟 ChatGPT 不一样,ChatGPT 是声明式的,你甚至可以让它扮演某个角色,但 Midjourney 是指令式的,你只能用指令让它画出你想象中的图片。当你能很稳定地出图后,再研究这些词不迟。对于普通人来说,真正阻碍我们的可能不是学会这些词语,而是我们的审美。
常见的品牌 Logo 一般分成以下 4 种形式:
Graphic Logo:
一般以图形为主,像 Apple、Twitter 以及 Midjourney 就是这种 logo。
Lettermark Logo:
一般用公司名字的首字母作为 logo 主体,像 Facebook、Tesla 还有 IBM (IBM 全称是 International Business Machines)都是用公司名的首字母作为 logo。
Geometric Logo:
几何图形组成的 logo,比如 Nike、百事可乐、万事达卡就是这个类型。
Mascot Logo:
以公司吉祥物为 logo 的相对来说比较少见,像米其林的 logo 就是吉祥物轮胎人,我最喜欢的烤鸡餐厅 Nando’s 就是一只🐔
其实常见的品牌 Logo 里其实还有一种,是文字组合式的,文字加上面任意一种,比如 Tesla 的 完整 Logo 就是 Tesla 加一个 T。但因为 Midjourney 在文字的生成上,有非常多的问题,所以不在本章进行介绍。

Graphic Logo
当你想用 AI 生成 Logo 的时候,我建议你选一个你认可的方向,然后再让 AI 生成。首先我们来分析一下 Graphic Logo 的特性:
Logo类型:graphic logo
Logo描述:比如猫
Logo风格: 扁平化设计「flat」,矢量图形:「vector graphic」,简洁:「simple」
根据特性撰写的 prompt ,核心的关键就是将风格描述清楚:
Graphic Logo 还有一种常见的设计,比如前面的例子里 Midjourney 的 Logo 就是这种,只需要在 graphic 后加一个 line 即可:
下方左边 4 个是没有加 line 的版本:

Lettermark Logo
这种类型的 Logo 看起来简单,就一个字母进行变形,但让 AI 生成反而效果很一般,而且有一个算是比较有意思的发现,用 A 字母做出来的 Logo 质量比其他字母做出来的 Logo 质量要好很多(非严格按照数据统计,仅个人感受)。这个类型的 Logo 有以下特点:
Logo 类型:lettermark
Logo 图形描述:纯字母
字体样式:可以按需加上喜欢的字体
风格:矢量图形:「vector graphic」,简洁:「simple minimal」
根据特性撰写 prompt(最后生成的是 A 和 C 的 logo,我个人感觉 A 的好很多),另外需要注意,这个例子其实是想说明,在 Midjourney 里,语法并不重要,lettermark 不一样要按照语法要求,写成 lettermark logo of letter A :

Geometric Logo
这个类型的 Logo 相对来说,虽然只有图形,但有很多玩法,介绍两个常用玩法:
循环重复:如果你用的是 iPhone ,可以看看 iPhone 里的照片应用的 Logo,它也是一个 Geometric Logo ,而且它是椭圆图形旋转重复,最后组合成了一朵花的形状。拆解一下,关键词是:
Logo 类型:geometric logo
Logo 图形描述:旋转重复「radial repeating」
风格:简洁「simple minimal」
让我们来写一个类似的 prompt:
渐变
另一个常见玩法就是渐变色,如果你用的是电脑的浏览器是 Edge,可以去看看它的 Logo,它的 Logo 就是一个渐变色,然后是个浪的外观。拆解一下,关键词是:
Logo 类型:geometric logo
Logo 图像描述:浪的形状「curved wave shape」,蓝绿渐变「blue green gradient」
风格:简洁「simple minimal」
让我们来写一个类似的 prompt:
最后生成的结果是这样的,我很喜欢花的第三个,浪的第二个:

Mascot Logo
这种吉祥物类型的 Logo,我认为是 Midjourney 最擅长的 Logo 风格。但也非常考验我们的想象力,当然我们也可以仅提供一些比较简单的词语,让 AI 帮我们生成,让我们一起来为一个机器人公司写一个 Mascot Logo ,拆解一下 prompt 关键词:
Logo 类型:mascot logo
Logo 主体描述:比如机器人「robot」
风格:简洁「simple minimal」
最后 prompt:
还有给一家泡面公司生成一个吉祥物又会怎样:
以下是生成的结果,我很喜欢泡面公司的 logo:

增加风格~艺术运动
前面生成的 logo ,有一些估计各位会觉得平平无奇,比如 Lettermark Logo,原因并不是 Midjourney 能力不强,而是我们给的指令太少了,只要在 prompt 里加几个单词,就能生成不一样的 Logo: 左边四个的 prompt 是这样的,我仅仅在原来的 prompt 上加了两个单词 Pop Art:

Pop Art 是什么?
波普艺术(Pop Art,又译为普普艺术或通俗艺术),是一种起源于20世纪50年代和60年代的艺术运动,它强调对大众文化、大众媒体和消费主义文化的反思和表达。Pop 来自“流行艺术”(popular art)一词里的 popular,由1956年英国艺术评论家罗伦斯·艾伟(Lawrence Allowey)所提出。
特点:
它的内容主体一般是大众日常生活中常见的物品和图像,如广告标语、杂志封面、食品包装等。用色比较大胆,同时线条比较简洁,强调物品本身的视觉效果和意义。
右边边四个的 prompt 是这样的,我在 prompt 里加上了 De Stijl 。
De Stijl 是什么?
它是一个荷兰艺术运动,始于 1917 年,致力于简化视觉元素,包括直线,平面和基本色彩。它的成员包括画家 Piet Mondrian 和 Theo van Doesburg 等人。De Stijl 的成员致力于将艺术与设计融合,以创造出具有实用性和功能性的美学。
特点:
常常用几何图形进行设计,如矩形和直线。用色基本只用基本色彩,比如黑、白、灰、红、黄、蓝。追求平衡和和谐,强调形式和结构,不注重细节和表现力。
场景3:App & 徽章 Logo
其实 App Logo 可以使用前一章提到的品牌 Logo,加上一个矩形边框就 OK 了,用 Figma 几步就能完成 😂,但如果你实在不想用 Figma ,也可以用 Midjourney 生成。不放看看你手机上的 App,想想 App Logo Prompt 应该怎么写?我用前一章的案例,写了两个 prompt ,输出的结果如下:
Logo 类型:mobile app logo
Logo 图形描述:iOS 的都是圆角矩形「squared with round edges」
Logo 图形描述,比如 「an icon for a Instant Noodles company」
风格:延续使用上一章提到的方法即可,我这加了个「pop art」
另外我发现在 Logo 图形描述前加 an icon for ,生成的 Logo 会更符合预期一些,右边是加了 an icon for ,左边是没有加的:

另外,Logo 图案是 Graphic 、Lettermark 还有 Geometric 的,会更符合预期:

增加风格~艺术家
本章再教大家一个方法,是增加艺术家的名字。首先需注意,Midjourney 支持大部分的艺术运动,但在艺术家的支持上,相对来说比较少,经过网友们的不懈努力,截止到 3 月 31 日,V4 已知支持的艺术家有 2000 多位,V5 有 100 多位。 其中在榜的 Logo 设计师,只有 Paul Rand 和 Saul Bass,Paul 是 IBM、英孚、NeXT logo 的设计师,Saul 是美国联合航空、AT&T logo 的设计师。 使用方法很简单,在 prompt 最后加上 by Paul Rand 即可:
当然也不是说只能加 Logo 设计师,加上没有设计过 Logo 的设计师名字,也很有意思。比如右边四张图我加的就是 Piet Cornelies Mondrian,第三张 logo 有 Composition II in Red, Blue, and Yellow 那味了。左边四张则是 Paul 的,第二张红色框加黑色 A,有他的经典眼镜 logo 那味,非常喜欢:

最后需要增加艺术家名,有可能出现以下情况:
多长图的风格都很像:这是因为某些艺术家有非常强烈的标志性风格,比如我很喜欢的 Piet Mondrian,你用他的名字,会发现可能生成的很多张图都是 Composition II in Red, Blue, and Yellow 的风格。生成的图看上去不太像该艺术家的风格:我自己测试,发现有两种可能,一种是模型并没有学习这个艺术家的作品(特别新的艺术家我感觉一般都不会收录),另一种可能是你的 prompt 里的一些词,跟该艺术家的风格有冲突,比如用了达芬奇 Leonardo da Vinci,但主体是个日本二次元小姑娘。
徽章 Logo
学校的校徽就是典型的徽章 Logo,使用方法也非常简单,只需要调整 Logo 类型为emblem 就可以,另外,跟徽章很搭的风格是 Vintage,两个都加上后 prompt 是这样的:
右边四个是加了 vintage 的,是不是很复古,我非常喜欢:

善用 no 参数,去掉不想要的元素
在徽章 Logo 的案例里,你应该还看过单色的徽章,比如校徽。但 Midjourney 有个习惯就是倾向于生成复杂的内容,生成单色内容,你可以在 prompt 里加入颜色,背景等等词,让其变得简洁。
还有一个技巧是用 no 参数。比如我想制作一个单色校徽,校徽主体是一本书,同时因为 Midjourney 对文字不是很擅长,我还要去掉 text。以下是我的 prompt,我在最后加了 no realistic color(没有颜色)text(字)。
然后我把上面那个 Instant Noodles company 的 prompt 也加了 no text,最后生成的两组图片是这样的(最后需要注意,no 参数在 logo 里使用时,no text 有的时候会失效,但如果你去掉 — 直接输入 no text 就会生效。
场景4:插画
撰写 prompt 核心是「描述清楚你想要的画面」,「越详细」生成的图片就约符合你的要求。要想提高 prompt 撰写能力,最好的方法是临摹别人的作品,然后自己尝试写一写,最后再看看别人的 prompt。要想描述清楚画面,可以从以下几个角度进行解构:
| 什么 | Stock Image | Logo |
|---|---|---|
| 类型 | stock photo of | graphic logo of |
| 主体 | two Asian men in suits shaking hands | cat |
| 背景 | in front of the main entrance of the office building | null(该场景不需要填写) |
| 构图 | focus on two hands | null(该场景不需要填写) |
| 风格 | background bokeh | vector simple minimal |
在风格这块,有两个小技巧,可以使用艺术运动,以及艺术家名字。
水彩
从本章开始,我们会进行一些更复杂的设计。水彩插画相对来说,应该会是小朋友比较喜欢的风格。
我们按照之前所学的模板来一步步写一下:
| 什么 | Prompt | 解释 |
|---|---|---|
| 类型 | light watercolor | 水彩 |
| 主体 | a sleeping cat | 睡觉的猫 |
| 背景 | white background | 水彩都是在白纸上画,所以这里加了白色背景 |
| 构图 | null | 不太重要,就让 AI 自由发挥 |
| 风格 | Studio Ghibli | 我很喜欢吉卜力风格所以加了个风格进去 |
然后再写一个带场景的:
| 什么 | Prompt | 解释 |
|---|---|---|
| 类型 | light watercolor | 水彩 |
| 主体 | children playing on the beach | 在沙滩上玩耍的孩子 |
| 背景 | white background | 因为一般水彩都是在白纸上画,所以这里加了白色背景 |
| 构图 | null | 不太重要,就让 AI 自由发挥 |
| 风格 | Jon Klassen | 他是我很喜欢的插画师,我很喜欢他的《This Is Not My Hat》 |
以下是生成的图片:

百科插画
除了水彩外,我很喜欢的另一种插画是百科全书手绘插画。我们一起画一副玫瑰:
| 什么 | Prompt | 解释 |
|---|---|---|
| 类型 | botanical illustration | 植物学插画 |
| 主体 | types of rose | 0一组玫瑰科普插画0 |
| 背景 | white background | 白色背景 |
| 构图 | null | 不太重要,就让 AI 自由发挥 |
| 风格 | Pierre-Joseph Redoute | 他是著名植物学家兼画家 |
再画一组恐龙:
| 什么 | Prompt | 解释 |
|---|---|---|
| 类型 | dinosaur scientific illustration | 恐龙科学插画 |
| 主体 | Tyrannosaurus | 霸王龙 |
| 背景 | white background | 白色背景 |
| 构图 | null | 让 AI 自由发挥 |
| 风格 | Andrey Atuchin | 著名俄罗斯古艺术家、生物学家、插画师 |
以下是生成的图片,看起来,Midjourney 并不知道霸王龙只有两只脚,哈哈哈,不过第一张真的非常像 Andrey 的风格:

绘本插画
绘本插画只要用好技巧五:增加风格——艺术家,基本上就能做出一些不差的插画。我绘本看得不算多,但应该不少人知道彼得兔,我们试试画一副和彼得兔类似风格的小猫:
另外我们也试试小熊维尼的插画师 E.H. Shepard 的风格(右边四张)。这里要额外说明下,为了让生成的结果更倾向于该作者的风格,我没在 prompt 里加入太多背景信息:

Behance 风科技插画
坦率说来,这个并不是一种插画风,但作为互联网行业从业人士,我觉得这个还挺刚需的,但需要注意,经过我的测试,只要在最前面加入 tech illustration 也能生成类似的风格插画,但效果比较一般,当我加上 behance style 后(Behance 简单理解是一个设计师分享作品的网站,分享的作品多与科技产品有关,如 App 设计等),就变得精致和漂亮了:
比如:一位在咖啡店坐在电脑前喝咖啡的女士

最后,这里面还有一个神秘参数,就是加上一些公司(比如 by Microsoft),我目前测试过像 Slack、Dropbox、Microsoft、Apple 感觉是有一点点差异,但我不知道 Midjourney 是怎么理解或处理这个词的,下面是两组案例,左边是微软的,右边是苹果的,除了苹果的第四个有个苹果 logo 外,我是看不太出来还有什么地方体现苹果的,个人觉得可能是在用色上会用该品牌的品牌色?

填色插画
最后一个要介绍的也不知道是不是插画,但可能不少朋友见过,就是那种可以让你在上面用蜡笔,或水笔填色的填色插画。我觉得非常适合让小朋友自己生成填色插画,然后打印出来,让小朋友上色。以下是霸王龙的例子:
| 什么 | Prompt | 解释 |
|---|---|---|
| 类型 | clean coloring book page | 填色书籍 |
| 主体 | Tyrannosaurus | 霸王龙 |
| 背景 | null | 让 AI 自由发挥 |
| 构图 | null | 让 AI 自由发挥 |
| 风格 | black and white | 黑白风格 |

场景5:头像
在 Stock Photo 一章中,介绍了 img2img 的方法,这个方法除了解决 Stock Photo 的那几个问题外,还很适合多个场景。本章会着重介绍用这个方法生成的头像的 prompt。并且从本章开始会逐步丰富我们的 prompt 结构,使其更加完整。
3D 卡通头像
| 什么 | Prompt | 解释 |
|---|---|---|
| 类型 | Portraits / Avatar | 原图是证件照,可以在 prompt 里加入「肖像」一词,或者「Avatar 头像」 |
| 主体 | smiling cute boy, undercut hairstyle | 这里可以是选填,你可以先不加这个描述,只填其余 prompt,然后如果生成的图片不像你。那你就在这里加点描述下你的头像的词,一般就是性别、样貌、发型、配饰(比如眼镜、耳环等)、表情等。注意,尽量挑特征比较强的部分输入,特征对了,生成的图片基本会有几份像 |
| 背景 | white background | 这里保留了证件照的白底,你可以加一些实际场景的背景,比如餐厅之类的 |
| 构图 | null | 因为我们预先传了图片,图片是张证件照,所以不填 |
| 风格 | 3d render,Pixar style | 因为目标是生成 3d 照片,所以这里加了 3d render(3d 渲染),以及我喜欢的皮克斯风格 |
| 镜头 | soft focus | 柔焦是指摄影中,使用柔焦镜头,使得拍摄的影像既清晰又柔和的效果。一般多在拍摄人像的时候使用,我在 prompt 里加上这个,可以使照片更柔和。你也可以不加。 |
| 参数 | —iw 2 | iw 是一个文字和 img 权重参数。数值越大,就越像原图,关于这个值的介绍,可以看高级参数篇 |
如果你生成的照片并不像预设的照片,可以在四张图里,挑一张比较像的,然后点 V 让模型继续生成,再继续挑一张像一点的照片,然后继续生成新照片,直到出现一张比较像的。这方法试过不理想,生成的图片还是跟原图不像,那就在 prompt 里加上「wear glasses(戴眼镜)」,真的很神奇,我只要加上戴眼镜就像非常多,如果你原图戴眼镜了,你试试在参数里加个 —no glasses,你会得到一张更不像你的图。
多参数同时使用
在使用 img2img 的方法生成头像时,我发现问题是「文字权重比图片权重高」,导致其生成的图片不像原图,iw 参数在 V5 里最多提升图片权重到 2,所以我就在想有没有可能进一步降低文字的权重。然后我就试了下 s 参数,发现的确好了很多。如果生成的图片还是不像,你可以在 —iw 2 基础上,再加一个参数 —s 200 ,注意同时用两个参数时,中间不要有逗号。我发现加了 s 参数之后的确像了很多,我个人猜测是 s 和 iw 连用会进步一削弱 text 的权重。s 是控制生成图片的风格化程度。简单理解,这个值越低会更符合 text prompt 的描述,数值越高艺术性就会越强,但跟 text prompt 关联性就会比较弱。所以如果你生成的图还是不像,就加大这个值,比如调到 500。
动漫风头像
与 3D 卡通头像一样,主要的修改是在图片风格上:
| 什么 | Prompt | 解释 |
|---|---|---|
| 类型 | Portraits / Avatar | 继续使用相同描述 |
| 主体 | smiling cute boy, undercut hairstyle | 继续使用相同描述 |
| 背景 | white background | 继续使用相同描述 |
| 构图 | null | 继续使用相同描述 |
| 镜头 | null | 继续使用相同描述 |
| 风格 | anime, Studio Ghibli | 制作动漫风的头像加了 anime(动漫),吉卜力风格 |
| 参数 | —iw 2 —s 500 | 注意同时用两个参数时,中间不要有逗号 |
赛博朋克头像
也是只需要改一下风格和背景即可:
| 什么 | Prompt | 解释 |
|---|---|---|
| 主体 | cyberpunk robot face, holographic VR glasses, holographic cyberpunk clothing | 加了脸的修饰,还有戴上 VR 眼镜,穿上赛博朋克风衣服 |
| 背景 | neon-lit cityscape background | 为了让图片更像是赛博朋克,就加了个霓虹灯城市背景,让其看起来更有赛博那味 |
| 风格 | Cyberpunk, by Josan Gonzalez | 加了赛博朋克风格,以及我非常喜欢的赛博朋克画家 Josan Gonzalez |
Midjourney 对亚洲人的理解还不是很行 ,大家可以在生成的照片中换脸就很像了。
神秘的 blend 功能
这个技巧,说实话,我感觉不能称其为技巧,但这又是一个 Midjourney 非常重要的 feature,所以在这里着重介绍一下。这个功能使用起来非常简单,在 Discord 输入框里 /blend,然后点击这个菜单:

之后你的输入框就会变成这样:
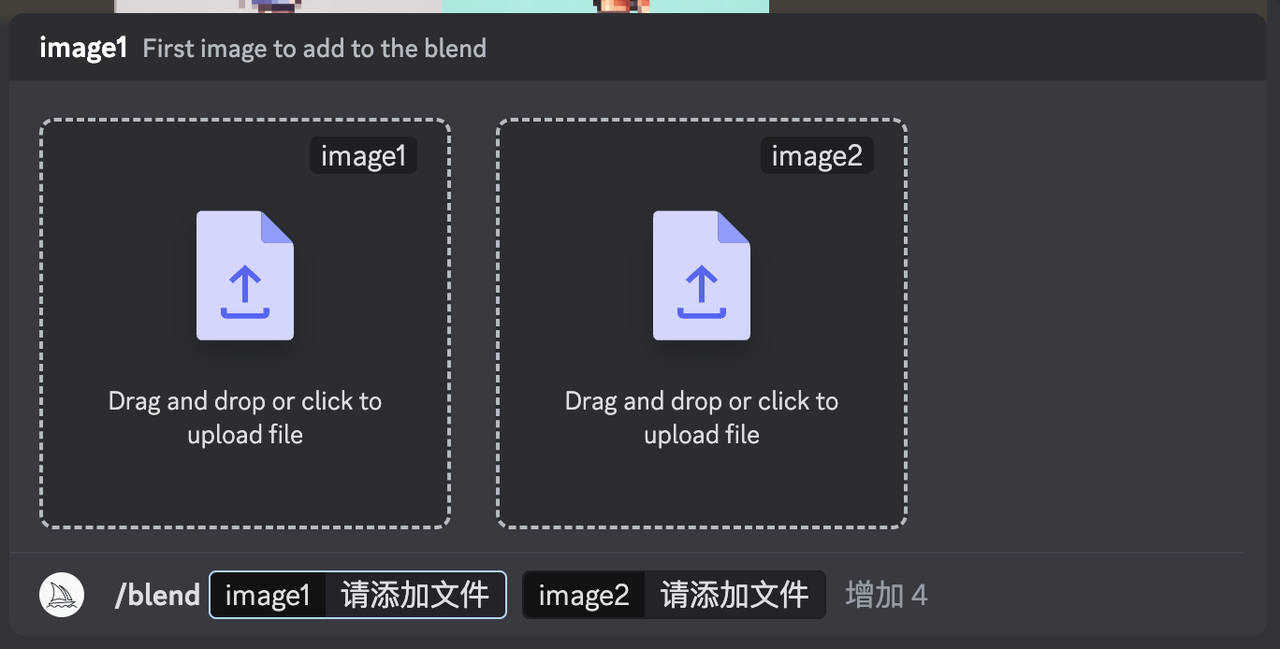
然后你就可以点击这两个框,然后选择你电脑上的照片,添加完成后,大喊一声「使用融合卡」(不是),然后点击回车:
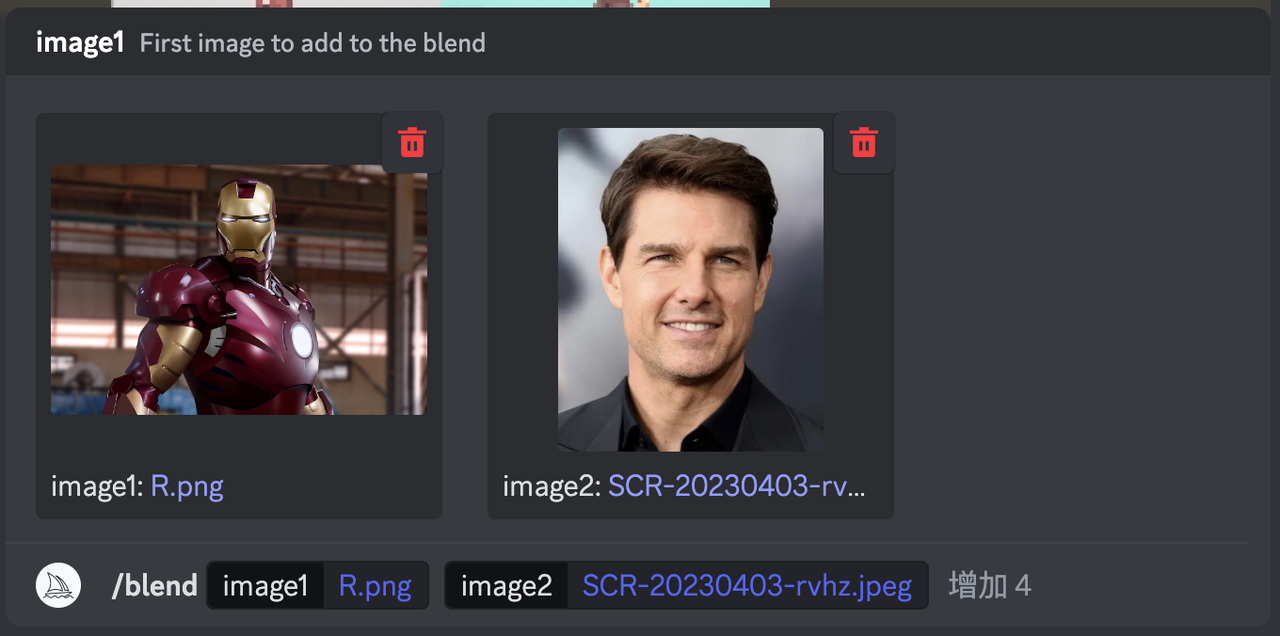
然后 Midjourney 就会生成这样牛逼的结果,左边是融合钢铁侠,右边是融合巴斯光年:

我本来打算用这个方法用于生成头像,但我发现只要用自己的照片,融合其他风格的照片,效果都不太好,目前实验下来效果最好的是名人头像,我的感觉是因为 Midjourney 喂了不少名人的头像给模型,所以这种融合的效果都很好。但我觉得它真的很适合做头像,将自己的头像跟另一张图片融合一下,就能生成一张不错的图,方便又快捷。可惜目前这个功能感觉还不太好用。当然这个功能还不仅仅止于此。
场景6:游戏
Prompt 真的越长越好吗?按照 Midjourney 的官方文档里的说法,并不一定:
有一些词非常重复,比如 8k、UHD、Ultra Quality,他们都在说一个事情,就是高清,加多了也不会有叠加作用。
很多词你根本不知道为啥需要,但好像每个人都加了。比如 8K 这些词,你有想过这个词是有必要的吗?是有用的吗?但实际上这些词官方并不推荐使用,这些词甚至对你的图会造成破坏(详见 Midjourney 官方 FAQ 一章)。如果你看完我的教程,你会发现我讲的例子里,很多图只要很少的 prompt 就能描述清楚,生成的图片也不差。当然我并不是说,不能写很长的 prompt,如果你生成的内容本来就很复杂,那写长一点也没所谓,但写完问问自己,这有必要吗?
像素游戏,像素风格一般有:8-bit/16-bit/32-bit
最近塞尔达发布了最新作《王国之泪》,喜欢他们的天空岛的设定,所以用 Midjourney 生成了一个 16-bit pixel art 版本:
类型是什么?
主体是什么?
背景是什么? null 主题描述里其实已经有背景了(clouds),所以我就没重复写
构图是怎样的? null 不太重要,就让 AI 自由发挥
用什么镜头? null 不太重要,就让 AI 自由发挥
是什么风格? 因为是
null 没有加任何参数
| 什么 | Prompt | 解释 |
|---|---|---|
| 类型 | 16-bit pixel art | 16 bit 风格 |
| 主体 | island in the clouds, ancient ruins | 天空岛,岛上有遗迹 |
| 背景 | null | 让 AI 自由发挥 |
| 构图 | null | 让 AI 自由发挥 |
| 镜头 | null | 让 AI 自由发挥 |
| 风格 | Zelda style | 复刻塞尔达,所以加了塞尔达风格 |
再生成一个宠物小精灵的场景:
| 什么 | Prompt | 解释 |
|---|---|---|
| 类型 | 8-bit pixel art | 换成了更复古的 8 bit 风格 |
| 主体 | types of Pokémon | 我想让 AI 生成宠物小精灵图谱一样的内容 |

3D 游戏~场景
在 3D 场景设计里,我最喜欢的应该是像素风 3D 微缩场景,写一个 prompt 给大家看看:
| 什么 | Prompt | 解释 |
|---|---|---|
| 类型 | isometric clean pixel art | 问了 ChatGPT |
| 主体 | robotics lab | 机器人实验室 |
| 背景 | null | 让 AI 自由发挥 |
| 构图 | null | 让 AI 自由发挥 |
| 镜头 | null | 让 AI 自由发挥 |
| 风格 | null | 让 AI 自由发挥 |
以下左图是火星工厂,右图是机器人实验室:

3D 游戏~人物
主体描述我就不多说了,更多是分享 3D prompt 的必要的要素:

3D 游戏~装备
游戏装备非常非常多,我只介绍一些我了解的,首先是戒指,多大数的游戏戒指都是那种印章戒指(signet ring)
另外一个可能常见的是装备集(我不确定这个中文是否正确,英文叫 Item Collections),写法是这样的:

控制变量法渐进优化
很多人把 AI 生成图片比喻为炼丹,我觉得非常贴切,很多时候,也不知道为啥,在 prompt 里加一点神秘配方,图片就会很不一样。
不过我觉得虽然过程很像炼丹,但并不代表我们需要像古人那样,用撞大运的方式炼制丹药。我认为目前使用 Midjourney 最好的方法是:控制变量渐进优化法。
拿上面那个装备集的图片为例,我希望它生成的是装备,并且是一件件地排布,而且光剑的效果也很奇怪,首先我们来逐条排查 prompt:
从这个表里可以看到,我们发现了三个问题,其中第一个黏土风格问题,跟最后一个问题有关,此时我的建议是:
1. 每次仅修改一个,其余变量不变。
2. 修改完一条,效果符合预期后,再修改下一个。
3. 我的经验优先修改主体内容,因为主体有的时候会影响其余的变量。
4. 如果想确定这个修改是否具有一致性,或者说是否符合要求,而不是恰巧符合,可以用相同的 prompt 再生成一次。不过因为没生成一次都要花钱,所以这个是可选项。
OK,按照以上原则,我们修改一下我们的 prompt,看看生成了什么,的确加了 different types of 后,光剑就多了,问题解决了:

然后我们修改下 blender 3d,将其改为 clay render (黏土渲染),我改完之后发现生成的结果(左边四张),好像质感还是差了一点,于是我又试了下保留 3d blender 加 oily 的效果(中间四张),以及 clay render 加 oily 两个一起用(右边四张)。

我个人觉得好像两个都改了效果是最好的(右边四张)。
对比一下最开始的 prompt 生成的图片,是不是最终的图片效果更好?所以这个技巧主要想告诉大家,写 prompt 没有必要照抄答案,你也有能力自己写好 prompt。
游戏设定稿
游戏这一章,再介绍一个可能会用到的一个场景人物设定稿,prompt 如下:

场景7:实物
玩具
OK 言归正传,从本章开始,我们会逐步丰富我们的 prompt 框架,让图片有更多的细节。实物生成的第一个是场景是玩具,是个非常有意思的场景。
另外,这个场景如果能跟 3D 打印机结合一下,我觉得会非常赞。不知道有没有有志之士能实现一下。
再解释下 prompt 有哪些更新,从实物这张开始,我讲「背景」调整为「环境」,即主体环境,包括背景、灯光等等:
| 什么 | Prompt | 解释 |
|---|---|---|
| 类型 | product photography | 产品照片 |
| 主体 | Stormtrooper, plastic, toy | 风暴兵和达斯维达为例。因为手办一般都是塑料玩具,所以加了两个词 |
| 背景 | white background, studio lighting | 突出手办,强调一下白色背景 灯光:增加一些灯光,突出产品 |
| 构图 | null | 让 AI 自由发挥 |
| 风格 | hand painted | 风格应该只有手绘 |
另外一个是游戏王里的蓝眼白龙,可惜 Midjourney 并不知道啥是 Yu-Gi-Oh,只能按字面意思生成了一个:

Midjourney 对美式动漫或电影作品支持会好很多,比如冰与火之歌里的龙妈(只是龙有点诡异),还有圣女贞德:

增加风格——国家
说到手办,大家应该第一反应会想起日本,再介绍一个技巧,在 prompt 里加入 Japanese style 即可,拿圣女贞德作手办,以及之前做的 logo 作为例子:

圣女贞德是不是有种 FF 的感觉?Logo 也比较简洁,猫的外观也有点像动漫里猫的外观,当然除了 Japanese 还有 Chinese(左边4张),甚至 African Style:

增加权重
各位有没有发现,上面那个 Chinese 手办生成的结果好像只有第三张是中国人面孔?原因是 Chinese style 的权重太低,所以仅输出了一个结果。你在实践的过程中,也肯定会遇到,AI 忽略了某些 prompt 词的情况,比如你提到画面中要有一只鸟,但它就是没画出来。
那为何会产生这样的结果?原因 Midjourney 的 prompt 权重是按照顺序逐个降低(详情请见我翻译的 Midjourney 官方 FAQ),在我们上面的 prompt,我们将 Chinese Style 放到了最后,所以生成的结果也是最少的。忽略了某些词,这个原因暂时为止,但应该很可能是权重导致的问题。
增加权重的方法有很多,最简单的方法就是调整顺序,比如将上面的 Chinese Style 放到最前面(然后生成的结果就是眯眯眼 style 了 🤣,我生成了两次,第二次好一些):
调整下顺序,效果就大不一样,所以各位不要迷信所谓的 prompt 模板,多试试。

第二种方法是 Slider 方法。
你需要在 prompt 最后加 ,然后加上你需要调整权重的词语,接着再加 ,最后加上权重值。比如还是上面的例子,我想突出 Chinese style 但不想调整顺序,就可以改为:
然后你会发现,好像权重太高了,生成了跟 prompt 无关的图(下方左图),那我们可以在原来的基础上,再加以下 Joan of Arc 的权重(下方右图):
你可以看到,调整参数后,生成的 4 张图有 2 张具备较强的 Chinese 风格:

不过坦率说来,这个方法,并不特别适合这个案例,调整主体内容,或者顺序, ROI 会更高一些,这个方法更适合 miss 掉某个 prompt 词时使用,比如官方的案例是这样的:
生成的图片里(左四张图),猫咪们都看着你(你可能才是 crying woman 😂),如果用 slider 的功能(右边四张),crying woman 就出现在画面里了:
另外需要注意,slider 可用的参数有 0.25、0.5、0.6、0.7,也可以用这个方法降低权重,区间是 -0.7、-0.6、-0.5、-0.25:

如果你用了 slider 还是没有出现应该有的画面,那还有一个大招 cowbell,坦率说来,这个并不符合 Midjourney 的官方最佳实践,但的确是个可行的方法,以下面这个 prompt 为例,生成的图片里,woman 看起来并不 shy(左边四张图):
此时你可以重复重复再重复(我觉得这就是为何这个方法叫 cowbell 的原因):

食物
另一个我比较喜欢的实物是食物,食物讲究的是「色香味俱全」,所以在描述食物类的 prompt 时,可以往这三个方向想想:
- 色:食物是什么颜色的(可以通过食物的熟度来控制)。
- 香:照片没有香味,但我们可以把香气画出来。
- 味:照片也同样没有味道,那我们加一点细节装饰?比如撒上胡椒、盐、辣椒?
类型是什么?
主体是什么?
环境是怎样的?
构图是怎样的? null 不太重要,就让 AI 自由发挥
用什么镜头? 为了突出食物,我加了背景虚化,这是背景虚化的另一种表达(有景深)
| 什么 | Prompt | 解释 |
|---|---|---|
| 类型 | food photography | 食物照片 |
| 主体 | steak, medium rare, steaming, light garnishes, sitting on plate | 牛排,五分熟,带蒸汽,仅有一点配菜,放在一个碟子上 |
| 环境 | epic lighting | 为了突出食物,我加了个聚光灯 |
| 构图 | null | 让 AI 自由发挥 |
| 镜头 | depth of field | 加了背景虚化,这是背景虚化的另一种表达(有景深) |

善用灯光
摄影中,常用摄影灯光有以下几种:
1、主灯 (Key Light)
主灯是最基本的摄影灯光之一,通常放置在被拍摄物体的正前方或正侧方,用于照明主体,决定拍摄物体的主要明暗度。主灯通常是亮度最高的灯光。
2、填光灯 (Fill Light)
填光灯用于弥补主灯照射的阴影部分,调整阴影的深浅程度,使照片明亮一些。通常填充光应该比主光暗一些,以避免出现过度曝光。
3、逆光灯 (Back Light)
逆光灯用于照射被拍摄物体的背面,能够区别出主体和背景,并使物体轮廓变得清晰,常用于拍摄骨感、重物感和逆光效果的照片等。
4、环境光 (Ambient Light)
环境光就是摄影环境自然产生的光线,包括室内照明、自然光、街灯等,它可以补充被拍摄物体的表面,提升照片的自然度和真实感。
5、故事性灯光 (Special Light)
通常是为了制造出某种情境或者表达某种意义而使用的,例如烛光、亮光等。它们能够产生温暖、浪漫、神秘等场景和气氛,以探索和表达艺术的想象力和创造力。
基于这些灯进行排列组合,你会得到不同使用场景的灯光。灯光的细节种类,可以去我归纳的 Lighting List 里查看,我这里主要分享一些常用和易用的场景灯光:
Mood Lighting「氛围灯」
主要是通过在特定的环境中改变灯光的颜色和亮度等参数来创造一种特定的氛围,以营造舒适、浪漫、放松等感觉。从技术实现上看,Mood lighting则着重于灯光的颜色和亮度控制,注重创造强烈的视觉效果。 Mood lighting通常用于室内设计、酒店、餐厅及居家装饰等领域,旨在创造出一种特定的气氛和体验。
Moody Lighting「情绪灯」
它更强调在情感表达和为故事情节服务方面的应用,设计的目的是要把灯光与剧情完美结合起来,以展现角色的个性和情感世界。从技术实现上看,Moody lighting通常采用低亮度和大比例遮挡阴影,强调暗部的扫描,以增加画面的纹理和层次感。 Moody lighting通常用于影视制作、游戏界面、舞台表演等领域,设计的目的是为了增加故事情节的戏剧效果。
Studio Lighting「工作室灯光」
是一种专门用于摄影工作室、电视和电影等领域的照明设计。它将光源和灯具放置在一个专用的摄影工作室中,通过精细的照明来创造出各种不同的氛围和场景效果,以满足各种不同的拍摄需求。 Studio lighting 主要应用于商业摄影、时装摄影、艺术摄影、人像摄影、广告拍摄、电影和电视制作等领域,目的是通过精细的照明设计来突出主体的特点,达到最佳的拍摄效果。
Soft Lighting「柔和照明」
是指通过使用柔和、漫射的光线来创造出柔和、温暖的氛围效果。柔和的光线通常是通过使用的漫射灯具来实现的,较为常见的是壁灯、台灯、阅读灯等。 柔和照明效果可以降低照度,减轻视觉疲劳,创造出舒适的氛围和感觉。
Hard Lighting「硬朗照明」
是指通过使用聚光灯、筒灯等灯具来聚焦到一个特定的区域中,其光线是相对集中而直接的。 创造出刚硬、明亮的照明效果。硬朗照明常常用于展示场合,如美术馆、商场等环境,以突出展品或商品的特点和质感。
Volumetric Lighting「体积光」
是一种创造逼真渲染效果的照明效果技术。它通过在某些场景中添加灯光和各种视觉效果,如扩散、雾、粒子、阴影等,在照明场景中模拟空气中的粒子和尘埃微粒的现象,从而创造出动态、逼真、增强立体感和体积感的照明效果。 适用于多种场景设计中,如电影、电视、视频游戏、动画等领域。它可以让场景更加逼真、立体,增加场景的紧张度和视觉层次感,并带来更具有表现力的视觉效果。
Low-Key Lighting「低键照明」
指的是一种特殊的照明效果,该效果通常通过强烈的侧光或背光和阴影来创造高对比度的画面效果。低键照明的特点是明暗分明、阴影浓重、暗调占主导地位,常常构建一种紧张、神秘或黑暗的氛围。 低键照明广泛应用于电影、电视、摄影等领域中,常常用来表现悬疑、恐怖、犯罪等要素。
High-Key Lighting「高键照明」
这种照明效果通过使用明亮、均匀的光线来避免明暗对比并压低阴影的出现。这种照明效果特点是亮度高、细节丰富,适用于需要传递愉悦、轻松和开心氛围的场景和环境。 高键照明通常用于广告、情感电影、电视剧等中。
Epic Light「史诗光线」
是一种创建极富戏剧性、威严感和视觉效果的照明技术,它可以在场景中添加非常亮烈、盛大、壮观的光线,以吸引观众注意力并增加场景的震撼力。 Epic Light通常用于影视制作、游戏开发、演出等领域中,以营造出一种崇高、壮丽、宏伟的氛围,可以使观众在看到这些效果时,感到非常震撼和难以忘怀。史诗光线的特点是亮度较高、颜色鲜艳,通常用于表现重要的剧情点,如武器的激光、宇宙战争中的太阳和星星、幻想电影和电子游戏中的神秘光芒等。
Rembrandt Lighting「伦勃朗特效」
是一种起源于荷兰画家伦勃朗的照明效果,其主要特点是在人物脸部形成一个菱形的明暗分界线,嘴巴和下巴的一侧用阴影覆盖,人物的另一侧则被亮光照亮。 能营造出一种柔和而神秘的效果。
Contre-Jour「逆光照明」
指的是摄影师将光源放置在被摄物体的背后,令照射效果在镜头前面产生,形成被摄体轮廓明显的负片形态。 于光源位置造成的暗摄影整体的虚化,高对比度和鲜明的轮廓线可以带来文艺和抽象的氛围。
Veiling Flare「透镜毛玻璃」
指当光线从透镜或镜头穿过时,透过玻璃或镜头的反光或散射使得图像出现散射光线或最终成像看起来失真的现象。
Crepuscular Rays「黎明、黄昏光线」
也称为太阳光柱,是由日光在云层或尘埃中被反射形成的光线束。因为只有在日出和日落时才有足够的光线穿过云层或照射到恰当的夹角,所以Crepuscular Rays通常只出现在日出和日落时刻。 Crepuscular Rays通常会在云层上形成明显的束状光线,给人以美丽的感觉。
Rays of Shimmering Light「闪烁光线」
是指在光线散射和折射时出现的光线折射现象。在某些特定的环境下,光线经过不同密度和温度不同的气氛,会出现一种光线折射、散射的效果,从而形成闪烁光束效果。
Godrays「神光」
是一种由光线穿过云朵、树枝或其他障碍物时,形成的亮光条纹效果。Godrays通常在光线较强的时分出现,将光线分割成条纹状,形成一种梦幻般的效果,也被称为 "crepuscular rays" 的一种。
场景8:人物
名人照片
Midjourney 在 V5.2 版本认识很多名人,你可以在描述主体的时候,加上名人的名字,就可以生成该名人的照片,我们生成几个电影里的经典照片:

第一个是 Keanu Reeves,第二个是 Vito Corleone(我并没有输入主演人 Marlon Brando),两组图的 prompt 都非常简单,你可以尝试自己写一下😁
衣服模特
做衣服类电商的朋友可能会比较需要这个功能:
1、用 AI 生成一个虚拟人
2、然后将货物照片(比如某件衣服)传给 AI
3、AI 将虚拟人和货物的照片融合在一起
坦率说来,我觉得 Midjourney 应该是可以的,但目前的效果还不太好,要想实现这个需求,只需要用到前面介绍的技巧九里提到的 blend 功能,详细方法就不在这赘述了,大致就是我将商品图和人物图用 blend 功能融合了下:
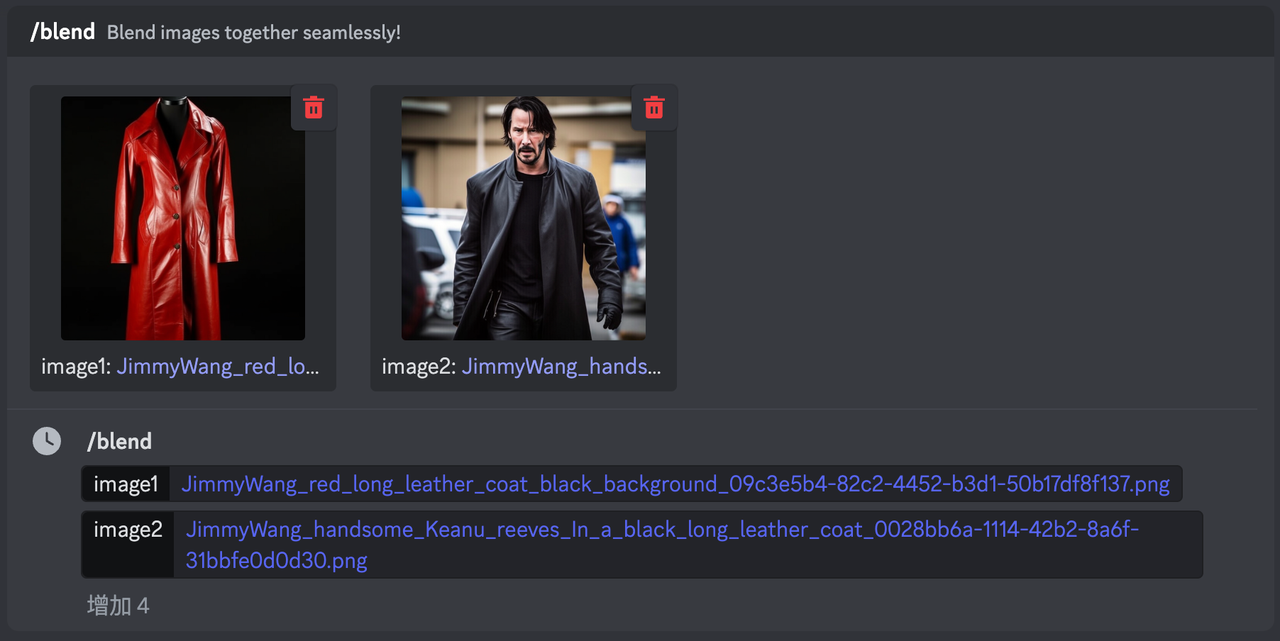
为了验证一致性,我生成了几张 Reeves 的图分别尝试了下,最后输出的结果是这样的:

整体来看,好像还行,但真的用在商品描述图里,我觉得还不太可能,因为里面的衣服跟原图差距还比较大(可以细看里面的纽扣)未来 Midjourney 可能会优化好这个功能,并且我觉得如果可以自己训练模型,这个功能实现起来应该不难。
老照片
这个算是名人照片的分支玩法,最近大家应该看到过很多类似的照片,其实 prompt 很简单,主体和背景大家用翻译软件搞搞就行:
类型是什么?主体是什么?环境是怎样的?构图是怎样的?用什么镜头?是什么风格?
| 什么 | Prompt | 解释 |
|---|---|---|
| 类型 | photography | 照片 |
| 主体 | a group of Chinese people gathered around Darth Vader | 一群中国人在围观达斯维达 |
| 背景 | on the street | 大街上 |
| 构图 | null | 让 AI 自由发挥 |
| 镜头 | fuji film | 增加了一个富士电影镜头 |
| 风格 | style of 1990s | 90年代风格 |
用类似的 prompt 生成了两组图片:

增加风格~年份
上面的老照片场景,我们用了 1990s 风格,严格地说这个 1990s 更适合放在主体或环境里,放在风格里也不是不行,因为不仅仅希望主体是 1990s 还希望图片生成的风格也是 1990s。这就是最后一种风格词用法:年代。拿插画那一章的两个 prompt 修改一下,我都没在 prompt 里加艺术家的名字,而是改为 style of 1920s,玫瑰的图有点那味,猫的图右上角那张太逗了。

Reeves 很简单,就是说明主体,然后注明穿着标志性的衣服,走在大雨里:
然后教父的那张就更简单了:
如何让 Midjourney 生成的人更具有多样性?
这里的多样性其实是指人的高矮胖瘦,甚至身体的一些特殊性等。大多数用 AI 生成的图片,人物都非常漂亮和英俊,但这并不好,这其实某种程度上代表了社会的偏见。所以我想在本章重点介绍下,如何让 Midjourney 生成更多样的人体。
方法一:Slider 方法
在上一章,我介绍了增加权重的方法,这个方法还可以帮助你生成不同体型的人物,以下是 Midjourney 官方社区的案例:
你可以控制 plus-sized 后面的参数,从而使画面中的人物变胖或者变瘦。这里需要注意,并不是负数就是越瘦的意思,而是削弱了 plus-sized 权重,如果你的 prompt 词是 thin 你加个负数 slider 参数那就是变胖了:

方法二:直接描述
Midjourney 是知道一些多样性的词语的,比如:
- blind:失明
- deaf:聋
- cerebral palsy:小儿麻痹
- accessibility:行动不便

场景9:风景
实物和人物介绍完,介绍一下风景。坦率说来,我并不擅长摄影,所以这三章写得可能会不太专业。我更多地是介绍方法,以及告知大家可能性。
微缩景观
风景大片,我觉得大家应该都在各大平台看过了,所以本章不会介绍太多常见的风景制作方法。而是介绍一些少见的,我这里介绍一个比较有趣的类型:
| 什么 | Prompt | 解释 |
|---|---|---|
| 类型 | Miniature faking | 迷你化仿效果(Miniature faking),也称为玩具世界效果,是一种通过特定的拍摄和处理技术来创造出一种缩小的场景感觉的方法。这种技术可以让实际大小的对象看起来像是一些小的塑料或金属模型。 |
| 主体 | Train Lines | 火车线路 |
| 风格 | style of Japanese | 我想要那种日本火车style,所以加了这个参数 |
另外还制作了一个火星工厂:Mars Factory

另外,我还很喜欢用这个效果制作一些多肉植物的照片,主体只要填写:cute mini Haworthia cymbiformis plant in a pot,或者 cute mini Aloe plant in a pot :

建筑
这里只介绍一种用法:对于人造物件,可以在主体里加入由 某某某 制造。以建筑为例,也不需要在 prompt 里加类型:【如:香港理工大学设计学院大楼的设计师 ~ Dame Zaha Mohammad Hadid】
右边是 Frank Gehry:

如果你对建筑感兴趣,不妨试试两种风格的建筑融合在一起试试,说不定会碰撞出有意思的设计。
改变相机与镜头
有些朋友用过一些手机 App ,它并不像 PS 工具那样,允许你修改图片的白平衡等参数,而是让你体验用旧相机(如胶卷相机)拍照,虽然本质上来说,它也是通过各种参数来模拟当年的相机效果,在 Midjourney 里,你也可以通过增加相机或者镜头的名称,从而达到类似的效果。根据我的实验,Midjourney 可以改变以下几类:
1、相机:支持不同种类的相机,比如运动相机 GoPro
2、胶卷:比如 8 mm 电影胶卷
3、镜头:比如 15 mm 镜头
4、相机设置:比如长曝光、双重曝光
5、景深 & 焦点:比如深景、浅景,还有消失点
我很喜欢双重曝光的效果,以及长曝光:

不过各位使用时,需要根据自己的场景选择合适的相机和镜头,比如无人机视角,都不太适合拍近物:
GoPro / 运动相机视角 / 自拍,或者运动场景
Drone / 无人机视角 / 适合航拍,或者天空景色
polaroid / 宝丽来 / 应该不需要解释了吧
black and white film / 黑白照 / 应该不需要解释了吧
Kodachrome / 柯达生产的彩色幻灯片底片品牌 / 具有非常高的颜色鲜艳度、对比度和持久性。
shot on 8mm / 电影 8 毫米胶卷是一种便携式、简单易用的胶片,分辨率比较低 / 适用于拍摄家庭和旅游等普通场景
shot on 16mm / 电影 16 毫米胶卷 / 16毫米和35毫米主要用于制作电影、纪录片和商业广告。
shot on 35mm / 电影 35 毫米胶卷 / 16毫米和35毫米主要用于制作电影、纪录片和商业广告。
Microscopic / 显微镜 / 适合一些需要放大观察的实物
Fisheye Lens / 鱼眼镜头 / 鱼眼镜头可以将整个场景拍摄在一个范围内,这种镜头的视角通常在 100° 至 180° 之间,可以呈现出非常夸张的透视效果。
Wide Angle / 广角镜头 / 适合风景照,可以让画面容纳更多内容
Ultra-Wide Angle / 超广镜头 / 适合风景照,可以让画面容纳更多内容
Panorama / 全景 / 适合风景照,可以让画面容纳更多内容
Short Exposure / 短曝光 / 通常用于追拍运动员、表演者或动物等,或者是拍摄需要快速决定瞬间捕捉的场景,例如拍摄火车、汽车、快速移动的车辆等。由于短曝光时间的限制,这种方式可以冻结运动物体并防止出现模糊的情况。
Long Exposure / 长曝光 / 在长曝光的拍摄中,快速移动的物体会出现轨迹,例如流星、车灯、瀑布等,这种方式会给照片创造出愉悦而神秘的氛围。此外,长曝光可以用于拍摄夜晚的大片景象,例如景色、城市夜景、星空等。
Double Exposure / 双重曝光 / 双重曝光的技术,可以创造出疏密有致和扭曲的、手绘和黑白艺术风格的照片。这种技术在拍摄人像、风景和建筑等领域十分受欢迎,因为它可以创造出独特的环境、浪漫和奇异感觉的图像。
f2.8 / 2.8 光圈 / 在拍摄时,光圈值越大,相应的光线进入相机的量就越大,使得相机所获得的图像更亮。f:2.8 的值是一个比较大的光圈值,因此镜头具有很高的传光能力,适合在低光环境中使用。同时,在大光圈下可以创造出较小的景深效果,突出焦点主题而模糊背景或前景,从而产生轻柔的背景效果,适合拍摄人物肖像或商品照片等类似主题。
Depth of Field / 景深 / 是指在摄影中,被拍摄的画面中被认为是清晰的范围,也称为焦距深度区域,通常用来描述在照片中被认为是清晰的范围。
Soft Focus / 柔焦 / 指将相机镜头前加入一层特殊的滤镜,使被拍摄的主体轻微模糊以呈现柔和的美感效果。柔焦的视觉效果相较于深景和浅景来说更强调画面的情感主题,把重点集中在逐渐化解结构感的质感效果上,使它在照片上产生一种有点朦胧的妆容,刻画出一幅浪漫的画面。
Deep Focus / 深焦 / 将摄像头在一个较大的光圈下设置,保持整个画面都清晰锐利的技术。深景通常需要使用较小的焦距或较远的拍摄距离,以保持整个画面的清晰度,是类似于大景深的一种刻画效果。
Shallow Focus / 浅焦 / 将相机的光圈调整到一个相对较大的开口,以使摄影师可以根据需要保持相机在平面上的一个特定区域或主体清晰,而照片中的其他区域则变得模糊不清的技术。这种效果常用于摄影肖像,使人物在画面上的清晰度突出,并且画面背景透露轻微的模糊感,带来更具艺术美感的效果。
Vanishing Point / 消失点 / 消失点指的是位于无穷远处,用于视觉处理的一点。在透视绘画中,我们可以想象一个位于无穷远处的点,使得所有线条都向它聚拢。消失点可以帮助画家或摄影师达到精致的透视处理效果,从而创造出独特的空间感;
Vantage Point / 俯瞰视角 / 一般呈现的效果是照片中会有一个点是最高点,然后在此最高点斜上方拍摄
场景10:动漫
多种 Anime Style
在 niji 5 模型下,默认生成的内容都会自带 Anime 风格,你可以在 prompt 语句的风格部分中添加国家、年代和创作者,还有一种方法是加动漫风格,根据 Midlibrary 的统计,Midjourney 支持的 Anime Style 超过 120 多种。
我这里就不罗列了,详细的列表可以看我整理的 List 或者直接去 Midlibrary,它们总结的是真的好。这里只分享几个我觉得不错,且模型支持得也不错的风格(prompt 主体都是 Statue Of Liberty):
Chibi Anime Style
卡通迷你风格。是一种独特的绘画风格,特别受到日本动漫迷和卡通迷的喜爱。该风格的特点是将角色绘制成缩小版的样式,更加可爱和卡通化。在这种风格下,一些角色的头比正常比例大得多,人物的描绘也更加简化,并且动画在绘制时常常用短暂时间的快速动作来传递动态效果。
Gakuen Anime Style
指在日本动漫中常见的一种风格,主要呈现校园生活与高中生活的情境。这种风格的作品通常涉及到学生会、文化节、恋爱、友情、竞争等校园主题,角色也往往是年龄在16-18岁之间的学生。
Gekiga Anime Style
一种比较沉重、严肃的日本漫画风格,常常涉及社会问题、人生哲理等成人主题。这种风格的特点是以黑色、灰色为主色调,图像表现力较强,人物表情和行为也更加真实。
J Horror Anime Style
指恐怖题材的日本动漫风格,这种风格的作品常常涉及灵异、鬼怪、妖怪等超自然力量。
Jidaimono Anime Style
指日本历史剧题材的动漫风格,通常呈现古代日本的历史背景和文化特征。这种风格的作品往往描绘战争、家族斗争、忍者、武士道、神话传说等元素,以及用具有浓重日本特色的艺术表现手法来传递历史文化的内涵。
Kawaii Anime Style
一种非常可爱和萌的动漫风格,通常呈现出像动物、小孩、角色等可爱的形象。这种风格的作品以颜色鲜明、轮廓粗糙、脸部表情夸张为主要特点。
Mecha Anime Style
以机器人为主题的日本动漫风格,通常呈现出大型机器、机甲战争、铁甲舞者等元素。这种风格的作品常常运用科幻、未来世界设定、大规模战斗等元素,以及动态的战斗场面和机器人设计,塑造出复杂的机器人世界和角色人物关系。
Realistic Anime Style
一种真实主义的日本动漫风格,通常呈现出秉持着更加现实和真实的人物形象和情节。这种风格的作品表现力很强,人物形象、环境场景等具有更多的细节,刻画出更为真实的情感世界。
Semi-Realistic Anime
是在Realistic Anime Style和 Anime Style之间的一个中间状态的风格,风格上比较真实,但是仍带有一定的动漫风格。这种风格的作品通常涉及到带有现实性的情节和人物,但是也常常运用到动漫风格的表现手法。
Shoji Anime Style
按照日本漫画家小学馆长生涯逐步形成的一种风格。这种风格的作品,通常以聚焦单个人物或小团体的故事为主线。其特点是画面明亮,颜色和谐,人物表情和行为搞笑夸张,情节简洁易懂。
Kemonomimi Anime Style
一种带有动物耳朵和尾巴等特征的日本动漫风格,通常以人类或近似人类的形象呈现,但却带有不同种类的动物耳朵和尾巴等特征。这种风格的作品与少女漫画(girls' manga)、少年漫画(boys' manga)等风格都有一定的关系。
将图片转为动漫风格:这个用到我们之前教的 img2img 功能,你只需要在 prompt 里加入图片 URL,然后加上以下 prompt 即可(为了更像原图,我加了 iw 参数):
panel from manga --iw 2
另一个我加了Naoko Takeuchi(美少女战士的作者),模型还是不善于生成人手:

场景11:其他
贴纸
不知道有没有人和我一样有喜欢买贴纸贴笔记本电脑的习惯。某宝虽厉害,但我希望的东西比较非主流,有一些无法满足我的需求,所以就想到让 AI 帮我画一些,以下用风暴兵和达斯维达为例,写一组 prompt:
生成的结果是这样的,你会发现就是多了一个白边,并且是矢量图风格

剪纸
我非常喜欢那种有层次的剪纸风格(中文应该叫啥呢?我只知道英文叫 layered paper art)但这种要画出来,还挺困难的,于是想着用 AI 试试:
用上述的 prompt 生成的结果还挺不错的,但如果你看下图左边 4 张图中的第 3 张,会觉得框里的球很不现实,也不是我想要的那种 2D 堆叠的剪影,第 2 张和第 4 张更像是我想要的,修改一下,加个 diorama(二维平面图)。
voilà~ 加上后效果好很多(右边 4 张),太漂亮了,希望某宝有卖:

邮票
不知道各位是否还知道邮票这种东西,2023 年了,我还有集邮的习惯,所以我在想用 AI 生成邮票估计也很有意思,所以就试了下,让 AI 做几张星球大战的复古邮票:
主体是什么? Stormtrooper, red ink, 继续用风暴兵和达斯维达为例。然后我规定了邮票的颜色是红色
环境是怎样的? null 不太重要,就让 AI 自由发挥
构图是怎样的? null 不太重要,就让 AI 自由发挥
拍摄媒介是什么? null 不太重要,就让 AI 自由发挥
是什么风格? line engraving, intaglio 传统邮票当年工艺是母版印刷,一般是那种线雕、版画风格,所以我这里加了这两个关键词,一个指线雕,一个指版画。
参数 null 没有加任何参数

海报的做法:
主体是什么? Star War 星球大战
环境是怎样的? null 不太重要,就让 AI 自由发挥
构图是怎样的? null 不太重要,就让 AI 自由发挥
拍摄媒介是什么? null 不太重要,就让 AI 自由发挥
是什么风格? studio ghibli, retro anime 我想让 AI 搞一个吉卜力工作室复古漫画风的海报
参数 null 没有加任何参数
海报并不仅仅指电影海报,你还可以用它来做广告海报。广告海报则把类型换一下即可。但需要注意,广告海报里需要其他元素来体现「广告」,并不是说加了 advertising 就是广告了。
主体是什么? Darth Vader points his finger at the viewer 达斯维达手指指着观众
环境是怎样的? null 不太重要,就让 AI 自由发挥
构图是怎样的? null 不太重要,就让 AI 自由发挥
拍摄媒介是什么? null 不太重要,就让 AI 自由发挥
是什么风格? studio ghibli, retro anime 照旧
参数 null 没有加任何参数

看到别人的图,想知道它的 prompt 是啥
最简单的方法,当然就是直接问。如果问不到,倒是可以借助一些工具,Midjourney 支持图片转 prompt 功能。方法很简单。第一步在输入框输入 /describe:

点击 describe 后,会弹出一个添加文件的入口,上传文件,并点击回车。
Midjourney 就会返回结果,点击图片下方的 1、2、3、4 按钮,可以直接发 prompt 给 bot,让其生成图片,右边是分别用 #1 和 #4 prompt 生成的图片,我觉得用它来探寻原图的构图、主体、风格应该都不错,但不要预期能生成一个完全一样的图:

四、框架总结
经过几个专题的学习,我们基本将 text prompt 框架里包含的元素都过了一遍,但大家可能会觉得内容不好记忆,所以本章我会对框架进行总结。
官方框架
在做总结前,我想先介绍下 Midjourney 官方的框架:
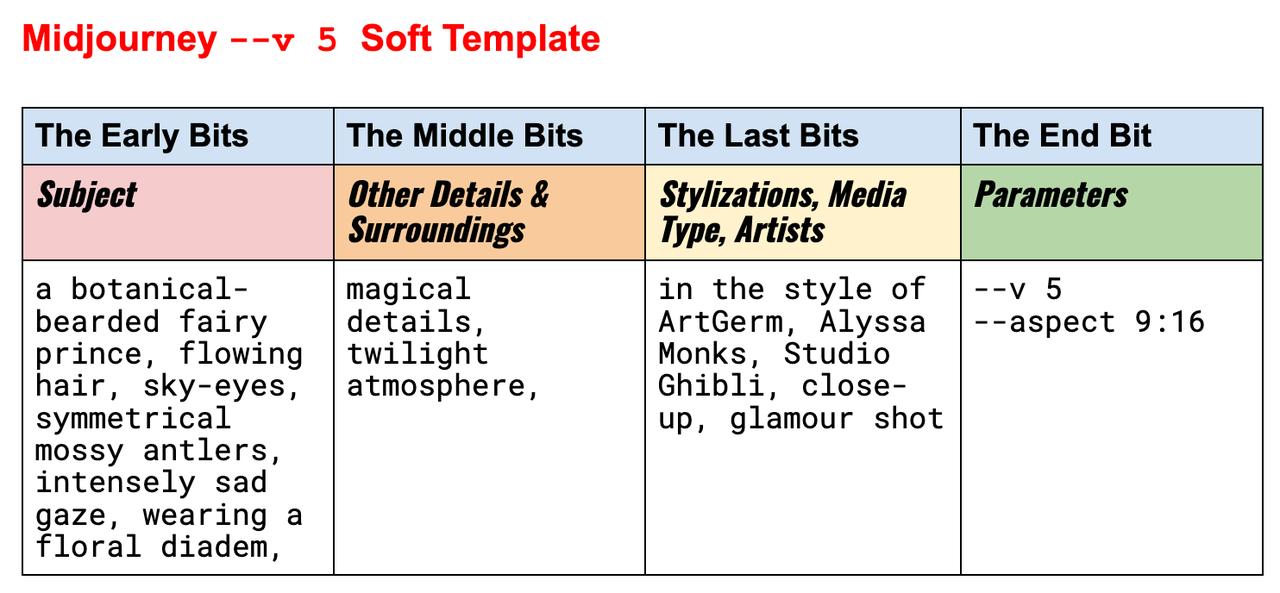
官方的模板很简单,分成四个部分:
1. 主体
2. 细节 & 背景
3. 风格、媒介、艺术家
4. 参数
我的总结
其实按照官方模板写,你已经能超过 90% 的初学者,但根据我的实验,我细化了他们的模板的,有以下调整:
将类型放在了最前面,因为 prompt 的顺序会影响权重(详情见我翻译的 Midjourney 官方 FAQ)
官方的 Middle Bits 和 Last Bits 写得比较宽泛,我对其进行了拆分,让大家更好记忆。
我用一个表格总结下这个框架,各位可以根据不同场景有选择地使用。
主体是什么? 描述下图片里的主体是什么,越多细节描述就越好,如果细节没有描述清楚,Midjourney 就会随机画给你。主体一般为两大类:Who:人物就描述下性别、样貌、表情、神态、衣着等What:实物的话就要描述它是什么、材质、颜色等等
环境是怎样的? 环境最主要的构成是以下几个:Background 背景,这个一般分为两类:纯色:主要是颜色为主,或者渐变风景:比如室内背景、街景背景等Light 灯光:光是从哪里投射到主体的?什么类型的光?Weather 天气:如果是室外的场景可以适当加一个,这样会让你的照片更自然。另外最好描述跟主体比较搭的背景,不然会很奇怪,如果你并不需要太特别的背景,那我建议你这一栏不用填,让 AI 帮你生成,一般不会太差。
构图是怎样的? 主体和环境都确认后,就要想想如何构图。比如:镜头的焦点在哪里?主体的朝向是是哪里?主体和背景的画面占比是怎样的?
拍摄媒介是什么? 这里有几个关键:相机型号胶卷镜头相机设置(如曝光、光圈等)
是什么风格? 可以用 4W 记忆:When:什么年代的风格?Who:你想要谁的风格?(人或组织)What:什么艺术类型的风格?或者艺术运动的风格?Where:什么国家的风格?
参数 这些类似照片的参数设定,比如:清晰度长宽比详情请见参数相关的介绍。
如何记忆?
这个模板看起来很长,但它跟各位拍照其实很像(只是顺序做了权重优化),各位想想自己的整个拍照的过程,是不是:
1. 看到某个物体/人物(主体),在某个环境下(环境)很漂亮
2. 拿出手机(拍摄媒介),打开相机,用手机取景器确定好构图(构图),按下快门
3. 最后 PS 一下(风格 & 参数)
五、官方总结常见问题
本章节,主要是翻译官方的 Discord FAQ 文章,我只挑了一些大家常见的问题进行翻译,各位可以在官方 Discord prompt-faqs 找到这些原稿。4K、HD 等所谓的 Rendering 词有用吗?官方解释 Rendering 词包括:
有用吗?官方的解释是:
意思就是会影响,有一定作用,但弊大于利。加入这些词,反而会破坏你的 prompt,特别是一些摄影场景,比如你需要用到诸如背景虚化等效果,再加上 4K 可能就会破坏背景虚化。
所以官方建议去掉这些词。
Prompt 里的词语顺序会影响结果吗?
官方解释:Word order matters. Early words are generally more influential.
顺序会影响结果,越早出现的词,对结果影响越大。所以我设计的模版才会将「类型」放在最前面。因为这是我的最重要的目标。官方还建议:
避免列举词语:例举的意思是在 prompt 里写多个同一个意思的词。
使用具体的相关词语:越具体生成的图片越符合 prompt。
用句子片段:就是不要像写雅思作文那样,写定语从句、长难句,而是将这些词切开。
避免使用4K、8K、16K等安慰剂词汇。
使用当前默认模型版本的中途图像的默认尺寸为 1024 x 1024 像素。
使用其他纵横比将生成尺寸不同但一般文件大小相同的图像。
在网络浏览器中打开 Midjourney 图像,或从 Midjourney.com 下载它们以获得最大文件大小。
您可以打印中途图像吗?
绝对地!您的打印质量只需遵循上述 DPI 规则即可。如果您想要高质量的打印,则每英寸需要 300 条信息。因此,默认的 1024x1024 像素中途图像将产生良好质量的 3.4 英寸 x 3.4 打印效果 (1024 / 300 = 3.41)。


评论留言